收录异常怎么排查:突然掉索引、部分掉索引与错误信号识别
收录异常怎么排查:突然掉索引、部分掉索引与错误信号识别
适合 SEO、技术、内容和增长团队在“索引突然下滑、部分页面掉索引、收录波动”时快速定位原因、止损和恢复。

一、先确认:这是“真实掉索引”还是“信号延迟/展示波动”
1. 先看三个事实源
不要一上来就改模板、删 canonical 或大规模提交重新收录。先用三个事实源判断问题是否真实存在:
- 索引覆盖/Pages 报告:看“已编入索引”“已排除”“发现但尚未编入索引”“已抓取 - 尚未编入索引”等变化。
- URL 检查工具:抽样检查首页、目录页、详情页、内容页、参数页,看 Google/搜索引擎对这条 URL 的抓取、规范化、可索引状态。
- 服务器日志/抓取日志:确认爬虫是否还在来,是否出现 5xx、429、超时、重定向链、渲染失败。
如果三者都指向异常,才算“真实掉索引”。如果只是在报表里降了,但抓取和页面状态正常,可能是延迟、聚合方式变化,或索引覆盖口径变化。
2. 用一句话判断紧急程度
- 突然掉索引:短时间内大面积 URL 从已收录变为排除,或者自然流量、抓取量、已编入索引同时下滑。
- 部分掉索引:只掉某个目录、模板、参数组合、某类内容,其他区域稳定。
- 波动但未掉索引:索引量上下浮动,但 URL 检查、抓取日志和排名没有同步恶化。
3. 一个快速判断表
| 现象 | 常见原因 | 先做什么 | 紧急级别 |
|---|---|---|---|
| 全站大面积掉索引 | robots/noindex/模板发布错误、服务器异常、站点迁移失误 | 立刻冻结发布,回滚最近变更 | 最高 |
| 某目录掉索引 | canonical 指向错误、重复内容聚合、目录被误设 noindex | 对比模板和目录级配置 | 高 |
| 参数页掉索引 | 规范化策略正常生效,或被误判为重复 | 确认这些 URL 是否本就不应索引 | 中 |
| 新内容不收录 | 抓取不足、站内链弱、内容薄、站点质量下降 | 看抓取、内链、页面质量 | 中 |
| 收录量下降但流量稳定 | 索引清洗、去重合并、口径变化 | 看排名和点击是否稳定 | 低到中 |
如果你需要先按“应该优先修哪一类 URL”做分组,可以先用 SEOSEM工具·Intent分析 把 URL 按意图、模板和商业价值拆开,再用 SEOSEM工具·ROI 决策工作台 排出修复优先级。
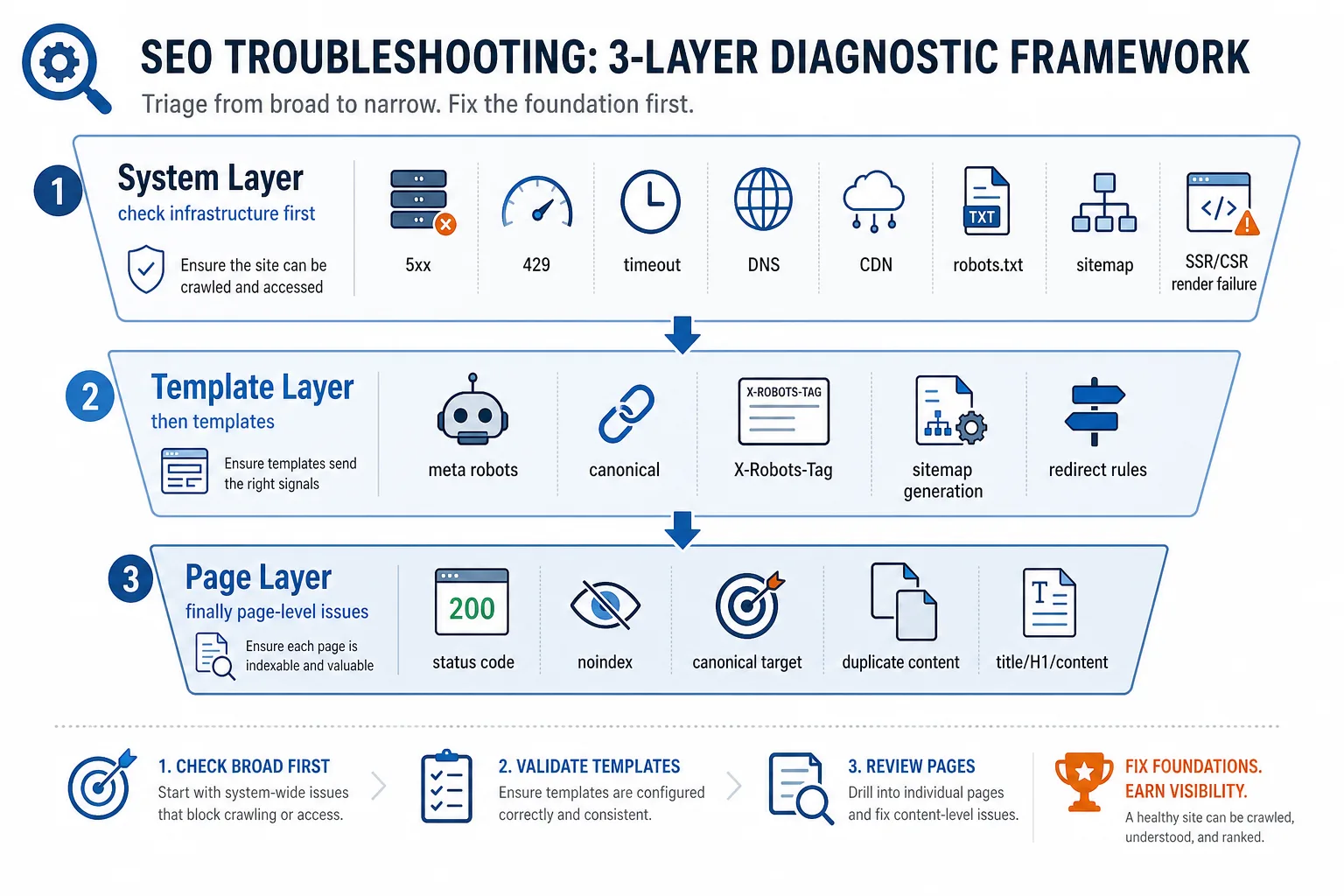
二、收录异常排查框架:先系统层,再模板层,再页面层
1. 系统信号:先排除“站点出问题”
系统层问题最容易造成“突然掉索引”。典型信号包括:
- 大面积 5xx、429、超时、DNS 故障、证书异常
- CDN 回源失败、缓存策略错误、边缘节点返回异常
- 发布后 robots.txt、站点地图、响应头被覆盖
- SSR/CSR 渲染失败,爬虫拿到空壳页面
- 迁移、改版、域名切换、HTTPS 改造后,旧 URL 没做正确 301
判断标准:如果很多不同模板、不同目录、不同语言的 URL 一起掉,而且日志里爬虫频率也下降,优先查系统层。
2. 模板信号:一改全站跟着变
模板层问题常见于 CMS、页面生成器、代码发布、SEO 插件。
你要重点检查:
<meta name="robots">是否被全站写成noindexrel=canonical是否全部指向首页、分类页或错误页面X-Robots-Tag是否在服务端被统一加上了noindex- 站点地图是否只剩少量 URL、是否包含 404/跳转 URL
- 多语言、分页、参数页是否被错误归一到同一个 canonical
3. 页面信号:单页、单模板、单目录异常
如果只有一部分页面掉索引,优先看页面级与目录级信号:
- 页面是否返回 200、还是 301/302/404/410
- 页面是否被加入了
noindex - canonical 是否自指,还是指向了别的 URL
- 页面正文是否与其他页面高度重复
- 标题、主文案、结构化数据是否大规模缺失
4. 内容与质量信号:搜索引擎在“主动收缩”
不是所有掉索引都是技术故障。搜索引擎也会因为质量、重复、薄内容而减少收录:
- 页面模板相似度过高,正文占比太低
- 列表页、筛选页、城市页、问答页批量生成,信息密度不足
- 站内大量近重复内容,canonical/去重策略不清晰
- AI 批量生成但缺少编辑、证据和差异化价值
如果你怀疑是内容层问题,可以用 SEOSEM工具·AI 风险评估 先筛出“高重复、低差异、低编辑密度”的页面,避免把技术故障和内容降质混在一起处理。
三、突然掉索引:先止血,再定位根因
1. 突然掉索引的常见触发器
“突然”通常意味着最近 24 小时到 7 天内出现了明确变化:
- 发布了带错误
noindex的模板 - canonical 被改成错误目标,导致整批 URL 被合并
- robots.txt 误封了重要目录
- 服务器异常让爬虫反复拿到 5xx
- 站点迁移后旧 URL 没有完成正确跳转
- 生成规则把重要 URL 改成了参数化、重复化路径
2. 三步止血法
第一步:冻结变更
暂停 CMS 发布、SEO 插件更新、模板上线、批量脚本、重写规则调整。
第二步:定位变更点
对比最近一次正常版本和异常版本,重点查:
<head>输出- 响应头
- robots.txt
- 站点地图
- 路由与重定向规则
- CMS 全局配置
第三步:只回滚可疑项
不要一次改十个地方。先回滚最可能导致全站异常的配置,再观察 24-72 小时:
- robots/noindex
- canonical
- 服务器响应码
- sitemap 与内部链接
3. 你应该看到的恢复节奏
- 0-24 小时:确认是否已恢复 200、可抓取、可索引信号
- 24-72 小时:爬虫重新访问,错误覆盖量开始下降
- 3-14 天:索引覆盖和点击恢复逐步显现
如果回滚后仍不恢复,说明问题不是单点配置,而可能是抓取预算、站点质量、重复内容或系统信号长期恶化。

四、部分掉索引:按目录、模板、意图分层排查
1. 先判断“掉的是哪一类页面”
部分掉索引最常见的分布方式:
- 目录级:/blog/、/product/、/location/、/help/ 中某一类掉了
- 模板级:详情页正常,列表页掉;或内容页正常,过滤页掉
- 参数级:带
?sort=、?color=、?page=的 URL 掉了 - 语言/地区级:某个国家站、城市站、语言版本掉了
- 意图级:信息型内容收录稳,交易型页面掉;或相反
先按意图、模板和商业价值分组,再决定修复顺序。不要把所有 URL 当成同一种问题。
2. 电商场景:最容易出问题的是筛选、排序、变体
电商站掉索引,经常集中在:
- 筛选页、排序页、分页页
- SKU 变体页
- 库存为 0 的商品页
- 促销活动页、临时专题页
判断原则:
- 该索引的主类目页、主商品页要保住
- 不该索引的筛选组合页要统一规范化
- 库存临时下架不等于永久删除
3. SaaS 场景:文档、帮助中心、博客、产品页分离
SaaS 常见问题是:
- 文档页面被 JS 渲染成空壳,爬虫拿不到正文
- 博客和产品页 canonical 互相指错
- 登录后才能看到的功能页误被公开收录
- 改版后旧文档和新文档内容重复
4. B2B 场景:行业页、解决方案页、案例页过度重复
B2B 站最容易出现“批量城市页/行业页”掉索引:
- 每页只是替换城市名、行业名,正文几乎相同
- 解决方案页、案例页、落地页互相重复
- 站内锚文本和内链全都指向同一少数页面
5. 本地服务场景:门店页、城市页、服务区页重复
本地服务常见问题:
- 一个服务复制成几十个城市页,内容高度一致
- 门店页缺少真实地址、电话、营业时间、地图信息
- 服务区页面和门店页面互相 canonical 到错误目标
如果你的站点在某个目录异常掉索引,先对比该目录和其他目录的模板差异,不要直接把所有页面都改成 noindex。
五、错误信号识别:看到这些,不要先怪“算法”
1. canonical 错误信号
canonical 是“规范化提示”,不是“强制收录按钮”。常见错误:
- 所有页面 canonical 到首页
- A 页 canonical 到 B 页,但 B 页内容并不是 A 页的主版本
- 参数页 canonical 到不相关分类页
- 多个不同内容页互相 canonical,形成环路
Google 对 canonical 和重复 URL 的处理可以参考:
- https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
2. noindex 错误信号
noindex 是最常见的“技术性掉索引”来源。重点检查:
- 页面模板里写成了
noindex - CMS 默认勾选了“禁止收录”
- 服务端通过
X-Robots-Tag下发了 noindex - 某类页面只在移动端/桌面端输出了 noindex
Google 对 robots meta tag 的说明见:
- https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag
3. robots.txt 错误信号
robots.txt 只控制抓取,不等于删除索引。常见误区:
- 误以为
Disallow就会让页面从索引中消失 - 先封抓取,再想用 noindex 去清理旧索引,结果爬虫进不去,清不掉
- 把重要资源、JS、CSS 也一起封了,导致渲染失败
robots.txt 的官方说明可参考:
- https://developers.google.com/search/docs/crawling-indexing/robots/intro
4. 重复内容错误信号
重复内容不一定是“抄袭”,更多时候是站内模板、过滤、分页、变体造成的近重复:
- 标题相似、正文相似、仅一个变量不同
- 多个 URL 显示同一商品或同一篇内容
- 站内搜索页、标签页、参数页被索引
- 同一主题被拆成几十篇薄内容
5. 系统信号错误信号
如果你看到下面这些,优先怀疑系统:
- 部分爬虫返回 200,但正文为空
- 所有页面都正常打开,但日志里爬虫抓取量骤降
- sitemap 能访问,但提交后“已发现 URL”增长异常慢
- 发布后索引减少与 CDN/路由/缓存变更同步发生

六、代码与配置示例:如何把正确信号放出去
1. 正确的 canonical + robots 组合
下面是一个适合“主内容页”的标准模板:
<head>
<title>企业级项目管理软件 - 示例站</title>
<link rel="canonical" href="https://www.example.com/product/project-management" />
<meta name="robots" content="index,follow" />
</head>
作用:
canonical指向当前主版本,帮助聚合重复信号index,follow明确允许收录和抓取链接- 适合产品页、文章页、服务页等应被索引的核心页面
2. 过滤页/参数页的规范化策略
下面示例适用于筛选页、排序页、列表参数页等“不是主收录目标”的 URL:
<head>
<link rel="canonical" href="https://www.example.com/shoes" />
<meta name="robots" content="noindex,follow" />
</head>
作用:
- 让搜索引擎知道主版本是
/shoes noindex阻止这类重复或低价值页面进入索引follow保留内部链接传递与发现能力
注意:如果这是你希望单独排名的核心页,就不要用 noindex。
3. 服务端统一下发 X-Robots-Tag
适合 PDF、DOCX、内部文件、测试环境或某类不该收录的资源:
location ~* \.(pdf|docx|xlsx)$ {
add_header X-Robots-Tag "noindex, nofollow" always;
}
作用:
- 不用改每个文件的 HTML
- 适合批量控制非 HTML 资源的索引策略
- 便于统一管理下载文件、白皮书、附件
4. robots.txt 只做抓取控制,不做错误清理
User-agent: *
Disallow: /cart/
Disallow: /checkout/
Disallow: /internal-search/
作用:
- 阻止搜索引擎抓取购物车、结账、站内搜索等低价值路径
- 减少抓取浪费
- 避免把无限参数页和低价值页面送进抓取队列
不要这样用:把已收录、需要清理的页面直接 Disallow,却不提供 noindex、404、410 或可抓取的删除路径。那样通常只会让问题拖更久。
七、按行业看:你最可能掉在哪一类 URL
1. 电商
重点排查:
- 类目页是否被错误 canonical 到首页
- 筛选页、分页页、排序页是否应保留索引
- 缺货商品页是 301、200 还是 404/410
- 变体页是否重复、是否需要合并
建议:
- 主类目页保留索引
- 可排序/可筛选组合做统一规范化
- 长尾商品页保留独立价值,不要全站同模板同文案
2. SaaS
重点排查:
- 产品功能页是否被误设
noindex - 文档中心是否因为 JS 渲染失败而空壳
- 博客更新后旧 URL 是否 301 到新版本
- 发布日志、帮助中心、API 文档是否形成重复簇
建议:
- 让核心产品页、解决方案页、文档页各自有清晰 canonical
- 保证首屏内容可抓取
- 用稳定的页面模板输出标题、摘要、H1、正文和内链
3. B2B
重点排查:
- 行业页、场景页、案例页是否批量复用同一份文本
- 地区页是否仅替换地名
- 下载页、白皮书页是否与博客内容高度重叠
- “联系我们”或表单页是否误进入索引主集
建议:
- 行业页要有行业数据、案例、流程、FAQ
- 场景页要有可验证差异,不要只换关键词
- 对低价值模板页使用统一的索引策略
4. 本地服务
重点排查:
- 门店页是否包含真实 NAP 信息(名称、地址、电话)
- 城市页是否有本地化服务证据,而不是复制全国通稿
- 服务区页和门店页是否互相冲突
- 地图页、预约页、热线页是否被错误 noindex
建议:
- 每个核心门店页都要有独立价值
- 城市页最好包含本地案例、服务范围和营业信息
- 避免一套模板复制几十个城市
八、恢复节奏:先隔离风险,再修复制度
1. 24 小时内:止损
- 冻结发布和配置改动
- 回滚最近一次 SEO/模板/服务器变更
- 修复最明显的错误信号:noindex、canonical、robots、5xx
- 记录影响范围:哪些目录、哪些模板、哪些国家/城市、哪些 URL 类型
2. 72 小时内:验证
- 抽样检查 URL Inspection
- 复查日志里爬虫是否恢复抓取
- 对比索引覆盖报告中的“排除原因”是否下降
- 观察流量、展示量、点击量是否同步回升
3. 两周内:制度修复
把一次事故变成制度,不要只做临时修补:
- 建立发布前 SEO 检查清单
- 让模板、CMS、运维、SEO 共享一份索引策略表
- 对“应收录/不应收录”页面分类固化到规则层
- 建立索引覆盖和抓取日志日报
- 对高风险目录做自动化监控
你可以把这套恢复优先级交给 SEOSEM工具·ROI 决策工作台 评估:先修能阻断全站收录的风险项,再修影响局部目录的次级问题。
九、最实用的排查清单:照着做就能定位八成问题
1. 先问 8 个问题
- 掉索引是全站还是部分目录?
- 最近 7 天是否发布过模板、CMS、插件或服务器变更?
- URL 检查结果里是否出现 noindex、canonical、重定向、软 404?
- robots.txt 是否变化?
- 站点地图是否变化?
- 日志里爬虫是否还在抓?返回码是否正常?
- 页面是否存在大面积重复、薄内容、参数化 URL?
- 掉索引的页面是否本来就不该被索引?
2. 再做 5 个动作
- 比对正常模板与异常模板
- 抽样检查 20 个核心 URL
- 看日志而不是只看报告
- 先回滚,再优化
- 用分组策略处理,不要一刀切
3. 最后留下 3 份制度文件
- 索引策略表:哪些页面可索引、哪些必须 noindex、哪些必须 canonical
- 发布检查表:上线前检查 robots、canonical、状态码、渲染、站点地图
- 异常回溯表:记录问题、影响范围、修复动作、恢复时间
十、结论:掉索引不是“算法玄学”,而是信号管理问题
收录异常的本质,不是“搜索引擎突然不喜欢你了”,而是你的站点在某个层级放出了错误信号:
- 系统层:爬不到、渲染不出来、返回码不对
- 模板层:全站一起 noindex、canonical 指错、robots 误封
- 页面层:重复、薄内容、参数页泛滥
- 质量层:搜索引擎主动收缩低价值页面
真正有效的排查方法,是先把页面分层,再把信号拆开,最后把修复顺序和风险隔离做对。这样你才能从“看见掉索引”变成“知道为什么掉、先修哪里、怎么恢复、如何避免再发生”。
如果你想进一步把“应收录/不应收录/待观察”分成可执行的内容池,可以继续结合意图分组、ROI 排序和风险评估工具,把收录治理纳入日常流程,而不是等掉索引后才救火。
下一课可以继续看: