SEO 大站治理怎么做:千万级 URL、抓取预算与站点收口
SEO 大站治理怎么做:千万级 URL、抓取预算与站点收口
大站 SEO 的核心,不是“做更多页面”,而是“让搜索引擎只花时间抓取、索引、理解真正有价值的页面”。
当站点规模进入千万级 URL 后,常见问题会集中爆发:
- 抓取预算被参数页、重复页、无效分页、站内搜索页吞噬
- 索引量远高于有效页面量,形成索引膨胀
- 模板雷同,导致内容差异不足、排名分散
- 信息架构失控,收口策略缺失,旧 URL 长期沉淀
- 新页面上线慢、收录慢、排名恢复慢,SEO 变成“技术债管理”
这类站点的 SEO,不是单点优化,而是治理工程。你要做的不是“让每个 URL 都被收录”,而是建立一套可验证的收口机制:明确哪些 URL 应该被抓取、哪些应该被索引、哪些应该被合并、哪些应该被禁止进入搜索引擎体系。
如果你需要先判断哪些页面值得投入,建议先用 Intent 工具 识别页面意图,再用 ROI Decision Workbench 做页面级收益优先级排序;若怀疑模板或生成内容存在质量风险,可结合 AI 风险分析 先筛出高风险页面类型。

一、先定义大站治理的目标:不是“多收录”,而是“可控收录”
1)大站 SEO 的四个治理目标
大站治理通常围绕四个目标展开:
- 控制抓取:减少无效抓取,提升重要 URL 的抓取频率
- 控制索引:避免重复页、参数页、低价值页进入索引
- 控制结构:让 URL、目录、模板、内链和站点地图统一
- 控制恢复:当误封、误删、误收口发生时,能快速回滚
2)大站的风险不是“页面少”,而是“页面无序增长”
千万级 URL 站点常见的失控方式:
- 商品、SKU、颜色、尺码、库存状态被拆成多个可索引 URL
- 筛选参数、排序参数、追踪参数被搜索引擎当成新页面
- 城市页、门店页、服务页批量生成但内容高度重复
- SaaS / B2B 站点把功能页、帮助中心、客户案例、变体页混在同一索引体系中
- 媒体站把标签、作者、分页、归档页放大成索引主力
治理的第一步,不是改标题、也不是堆内容,而是回答一个更基础的问题:
这个 URL 是否值得进入抓取队列?是否值得进入索引库?是否值得长期维护?
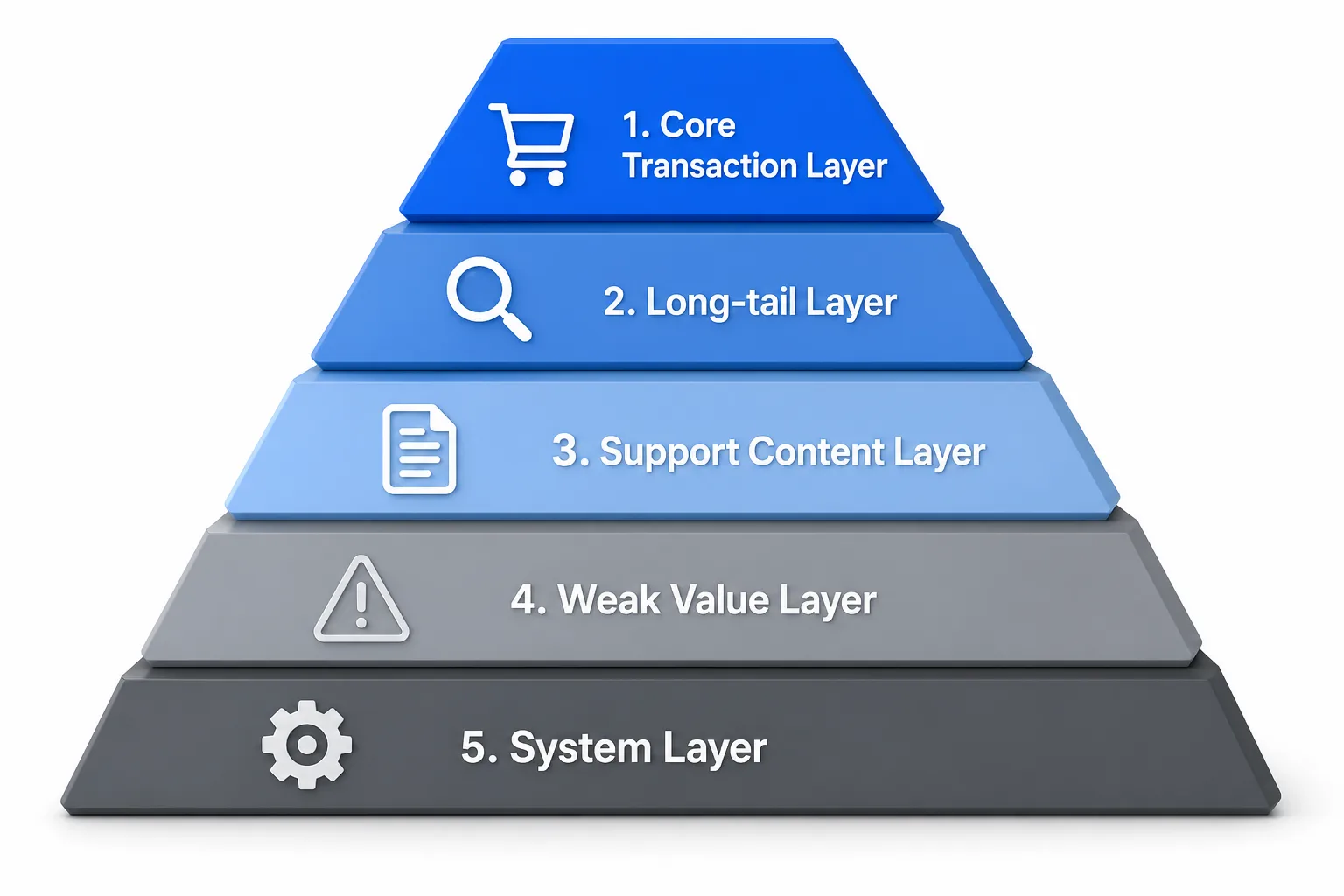
二、URL 分层:先把站点拆成“可治理的层”
1)用 URL 分层替代“全站同权”思维
大站必须做 URL 分层,否则任何技术策略都会失去边界。建议至少分成以下几层:
- 核心交易层:高转化、强需求页面,例如类目页、核心商品页、核心服务页
- 扩展长尾层:具备搜索需求的长尾组合页,例如城市 + 服务、品牌 + 型号
- 支持内容层:指南、FAQ、知识库、案例、媒体内容
- 弱价值衍生层:筛选页、排序页、分页页、标签页、站内搜索结果页
- 系统层:登录、购物车、结算、账户、后台、测试页、追踪参数页
每一层要有不同的 SEO 策略:
- 核心交易层:优先抓取、优先索引、优先内链
- 扩展长尾层:只保留有明确搜索需求且有独特内容的页面
- 支持内容层:按主题聚类,增强语义关联
- 弱价值衍生层:默认不索引,必要时只做可访问、不进索引
- 系统层:禁止抓取或彻底隔离
2)用“层级规则”决定 URL 去留
建议建立一个简单但可执行的分层规则:
- URL 是否有稳定搜索需求
- URL 是否有独特内容,不只是模板变量替换
- URL 是否具备商业价值或留存价值
- URL 是否会和其他 URL 产生重复、近重复或参数膨胀
- URL 是否能够被内链持续供给
如果五项里只满足一两项,这类 URL 大概率不应进入主索引池。
3)不同业务类型的分层重点
电商站
重点区分:
- 类目页:应作为主索引资产
- 商品页:重点资产,但要防止同款多变体泛滥
- 筛选页:只保留少数有搜索需求的组合页
- 参数页:大多应标准化或屏蔽
- 促销页/活动页:要有生命周期管理
SaaS 站
重点区分:
- 产品功能页:核心资产
- 方案页 / 行业页:按真实需求分层
- 帮助中心:高质量知识内容可索引
- 文档页:适合长尾,但需要结构化
- 登录 / 后台 / 个人中心:必须排除
B2B 站
重点区分:
- 产品目录页:核心交易或线索页
- 行业解决方案页:慎重做模板化扩张
- 案例页:有独立内容价值时可索引
- 地区页:必须避免“城市名替换型垃圾页”
本地服务站
重点区分:
- 主服务页:核心资产
- 城市页 / 区域页:只有在内容、供给、服务能力真实存在时才扩张
- 门店页:要和营业信息、地图、评价体系绑定
- FAQ / 指南页:用于补充搜索需求
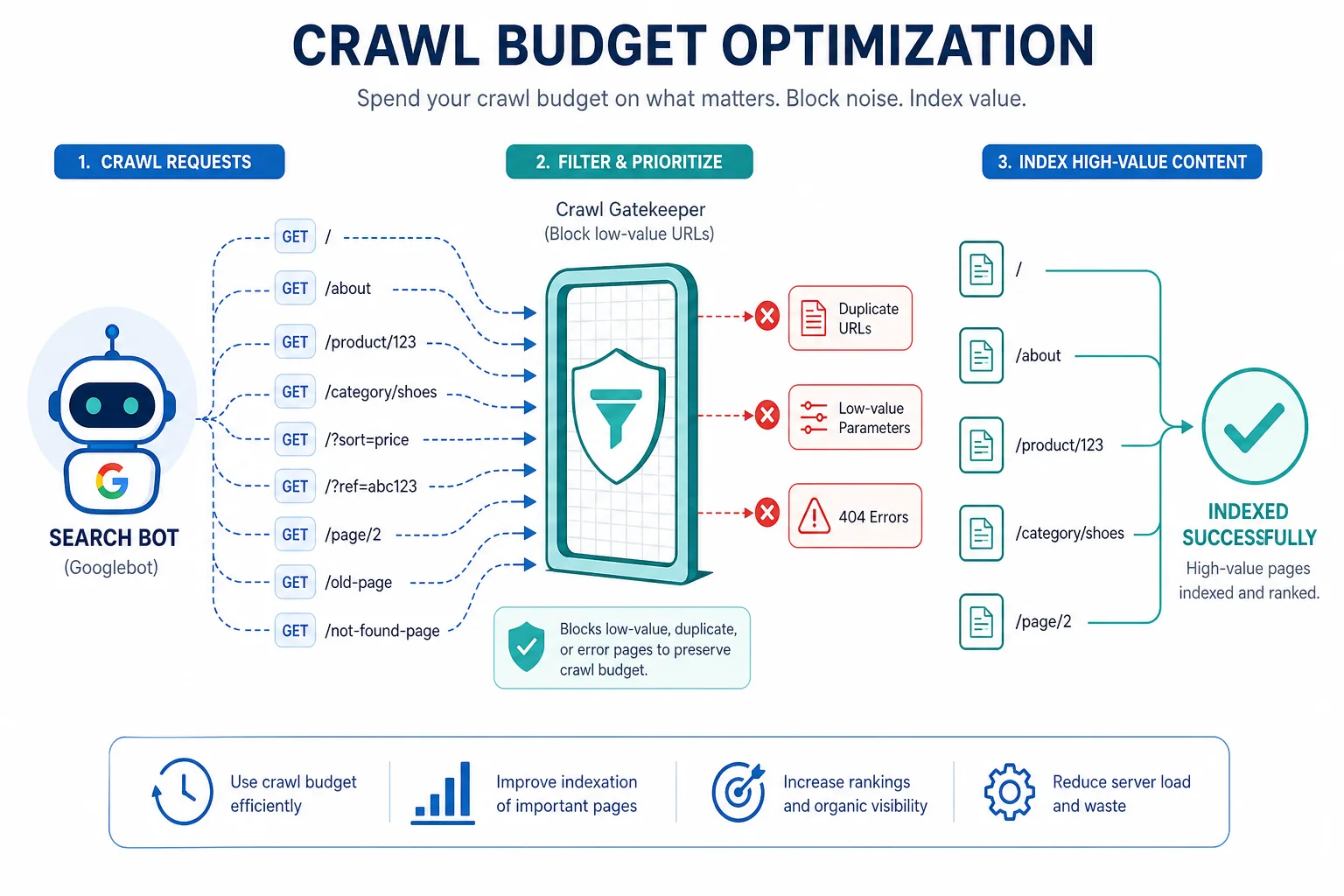
三、抓取预算:先管“爬什么”,再谈“排什么”
1)抓取预算不是神秘值,而是搜索引擎的资源分配结果
大站常说“抓取预算不够”,本质上是:
- 机器人把大量请求花在低价值 URL 上
- 重要页面更新不够快,抓取优先级被拖低
- 站点结构复杂,搜索引擎难以快速识别主次
Google 在公开文档中也明确建议大站重点关注可抓取 URL 数量、重复内容、服务器响应和站点结构,相关说明可参考:
- https://developers.google.com/search/docs/crawling-indexing/large-site-managing-crawl-budget
- https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt
- https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
2)抓取预算优化的优先级
建议按以下顺序处理:
- 删掉或隔离无价值 URL
- 减少重复内容生成
- 压缩参数组合
- 提升重要页面内链密度
- 让站点地图只保留高价值、可索引 URL
- 优化服务器响应,降低抓取成本
3)抓取预算的衡量指标
要判断抓取是否浪费,至少看这几个指标:
- 抓取日志中,搜索引擎访问的 URL 是否大量集中在参数页、分页页、站内搜索页
- 新增内容页是否在 24-72 小时内得到足够抓取
- 重要页面是否长期不被重抓
- 搜索引擎是否频繁抓取已重定向、404、软 404、重复页
- 站点地图提交的 URL 是否大量处于“已发现未抓取”或“已抓取未索引”状态
4)抓取预算的核心目标
不是“让蜘蛛多来”,而是:
- 让蜘蛛少碰垃圾页
- 让蜘蛛更快发现主页面
- 让蜘蛛更频繁重抓核心内容
四、模板收口:大站最容易被低估的技术债
1)模板重复会放大整个站点的低质量
很多大站不是单页内容差,而是模板导致“内容差异不足”。典型问题包括:
- 标题结构一致,只换一个变量
- 首屏内容重复,差别只在商品列表或参数表
- 页脚、推荐模块、面包屑、标签区块过于相似
- 城市页、行业页、专题页、活动页全部复用同一骨架
这样做的结果是:即使 URL 很多,搜索引擎也会判断“这些页面彼此太像,没必要都收录”。
2)模板收口的原则
模板收口不是“减少模板数量”这么简单,而是:
- 减少同义重复的页面类型
- 降低可生成 URL 的自由度
- 让每个模板对应一个明确的搜索意图
- 对弱价值模板默认设置非索引
3)模板治理的实操方法
建议按三步做:
第一步:模板盘点
把站内所有页面类型列出来:
- 类目页
- 详情页
- 列表页
- 筛选页
- 城市页
- 站内搜索页
- 标签页
- 专题页
- 文章页
- 帮助页
第二步:模板分级
给每个模板打上三类标签:
- 主模板:必须长期保留并优先优化
- 辅助模板:有价值,但不应无限扩张
- 弱模板:默认不索引或受控索引
第三步:模板收口
把多种近似页面合并到更少的标准模板上,减少页面变体。
4)模板收口的结果应该可验证
收口后要看:
- 模板数量是否下降
- 页面重复率是否下降
- 索引页中的低价值模板占比是否下降
- 核心模板的点击、抓取和收录是否上升
五、参数治理:大站最常见的抓取与索引黑洞
1)参数页为什么会失控
参数往往来自:
- 排序:sort=price_asc
- 过滤:color=red、size=m
- 分页:page=2
- 追踪:utm_source、cid、ref
- 站内搜索:q=xxx
- 会话:sessionid
如果不治理,这些参数会造成:
- URL 数量指数增长
- 同一内容被拆成大量可访问 URL
- 站点地图、内链、分页、筛选交叉放大
- 搜索引擎无法准确识别主 URL
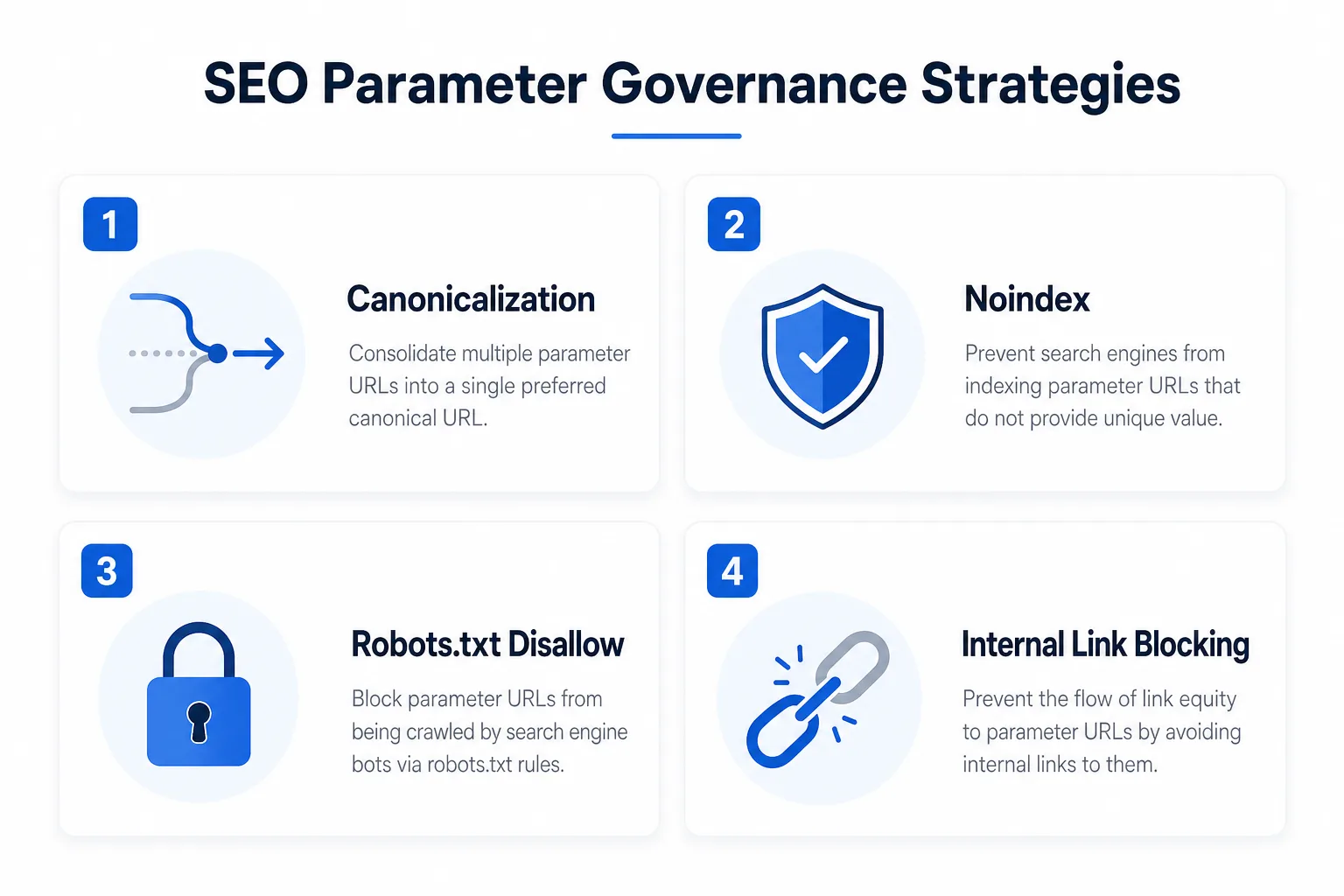
2)参数治理的四种策略
策略一:统一规范化
对于会产生重复的参数,统一 canonical 到主 URL。
策略二:禁止索引
对无搜索价值的参数页,使用 noindex 或在 robots 层做控制。
策略三:不生成可点击链接
很多参数页并不是“被抓到”,而是被站内链路主动喂给搜索引擎。
策略四:只保留少量有搜索需求的组合页
例如少数高需求筛选组合可以作为独立落地页保留,但必须有独特文本、内链和明确意图。
3)robots 与 canonical 的示例
下面是一个适合参数治理的 robots.txt 示例:
User-agent: *
Disallow: /search
Disallow: /*?sort=
Disallow: /*?sessionid=
Disallow: /*?utm_
Disallow: /*?ref=
Sitemap: https://example.com/sitemap.xml
作用说明:
- 阻止搜索引擎优先抓取站内搜索页和明显的追踪参数页
- 降低无效 URL 进入抓取队列的概率
- 保留站点地图入口,帮助搜索引擎集中发现主 URL
再看一个 canonical 示例:
<link rel="canonical" href="https://example.com/category/shoes" />
作用说明:
- 将带筛选或追踪参数的 URL 统一信号汇总到主类目页
- 防止同一页面内容被多个参数 URL 分散权重
- 帮助搜索引擎判断主版本页面
4)参数治理的常见误区
- 只在 robots.txt 里屏蔽,却不处理站内链接,导致 URL 仍大量生成
- 对所有筛选页一刀切 noindex,结果把有搜索需求的组合页也废掉
- canonical 指向不稳定版本,导致信号混乱
- 参数策略和站点地图策略不一致
六、索引膨胀:看起来收录很多,实际上风险更大
1)什么是索引膨胀
索引膨胀不是“收录多”这么简单,而是:
- 索引页面总量远超有效页面总量
- 大量低价值页面长期占据索引空间
- 真正值得排名的页面被稀释
- 搜索引擎对站点质量的整体判断被拉低
2)索引膨胀的典型信号
你可以从以下现象判断:
- 站点收录量持续上涨,但自然流量不涨反跌
- GSC 中“已编入索引”的页面里,参数页、分页页、标签页占比过高
- “已发现-未编入索引”大量堆积
- 首页、类目页、核心详情页抓取频率下降
- 搜索结果中出现大量薄内容页面
3)索引治理要区分三类页面
应索引页面
必须保留、持续维护,并进入主内链体系。
可访问但不索引页面
用户可访问,但不应占据搜索索引资源。
不应被发现的页面
系统页、测试页、重复页、垃圾参数页,应尽量不要进入公开可抓取体系。
4)索引膨胀的收口路径
建议按以下顺序:
- 先找出索引中的低价值 URL 类型
- 按模板/参数/目录批量处理
- 通过 canonical、noindex、robots、内链清理等组合手段治理
- 更新站点地图,删掉不该再提交的 URL
- 观察 2-8 周,确认索引结构回归健康
七、日志分析:大站治理不能只看收录,要看真实抓取行为
1)日志是抓取预算的真相来源
比起“猜蜘蛛会不会来”,日志能告诉你:
- 搜索引擎实际抓了哪些 URL
- 哪些模板被反复访问
- 哪些无价值路径吞掉了大量抓取
- 核心 URL 的抓取频率是否下降
2)建议重点看四类日志字段
- 请求 URL
- 状态码
- User-Agent
- 响应时间
3)一个简单的日志统计示例
awk '$12 ~ /Googlebot|Bingbot/ {print $7}' access.log | \
grep -E '\?|/search|page=[0-9]+|sort=' | \
sort | uniq -c | sort -nr | head -50
作用说明:
- 从访问日志中筛出搜索引擎爬虫请求
- 统计带参数、站内搜索、分页和排序 URL 的访问次数
- 快速发现最浪费抓取的路径类型
4)用日志反推优先级
如果日志显示:
- 70% 的爬虫请求花在低价值参数页
- 核心类目页 7 天才被抓一次
- 商品详情页更新后 3-5 天才被重新抓取
那么问题不是“多发内容”,而是“抓取路线错误”。你要先修站点结构和链接分发,再做内容优化。
八、优先级管理:不是所有 URL 都值得同等处理
1)大站需要页面级优先级矩阵
建议把 URL 按以下维度打分:
- 搜索需求强度
- 商业价值
- 内容独特性
- 更新频率
- 内链覆盖度
- 重复风险
- 抓取成本
2)优先级矩阵的用途
它能帮助你回答:
- 哪些 URL 应该优先进入站点地图
- 哪些页面应该优先做内链提升
- 哪些页面值得改模板
- 哪些页面应该做合并或下线
3)可以把 SEO 决策变成产品化流程
你可以把页面级优先级接入工作流:
- 高价值:进入主索引池,持续监测
- 中价值:观察点击和抓取表现,再决定是否放大
- 低价值:默认收口,不进入主链路
- 高风险:先做验证,再执行批量改动
如果你希望把“要不要改、改多少、优先改什么”变成可视化决策,可以用 ROI Decision Workbench 把页面收益、风险和执行成本放在同一张表里;若要快速排查某类 URL 是否容易生成低质内容,也可以用 AI 风险分析 做初筛。
九、行业拆分:电商、SaaS、B2B、本地服务分别怎么做
1)电商:重点管参数、SKU、筛选和变体
电商站最常见的问题是 URL 爆炸。
重点治理对象
- 分类筛选页
- 颜色/尺码/品牌参数页
- 商品变体页
- 库存状态页
- 活动页和促销页
推荐策略
- 主类目页做强,承接核心词
- 只保留少量高需求组合筛选页
- 变体尽量统一到主商品页
- 低库存、下架、过期活动页建立回收机制
2)SaaS:重点管产品页、文档页和帮助中心
SaaS 站点的挑战不是参数爆炸,而是“内容结构分散”。
重点治理对象
- 功能页
- 方案页
- 用例页
- 文档页
- 帮助中心
- 博客页
推荐策略
- 功能、行业、场景三层内容必须有清晰边界
- 文档页可规模化,但要避免标题和正文模板化
- 帮助中心与产品页之间建立强内链
- 对低意图文章页做归类,避免信息孤岛
3)B2B:重点管行业页、解决方案页和案例页
B2B 常见问题是批量生成行业页、地区页、解决方案页,但内容深度不足。
推荐策略
- 行业页必须包含行业痛点、方案、案例、FAQ
- 解决方案页不要只换行业名称
- 案例页需要真实数据、客户背景和结果
- 低质量的“城市 + 业务”页要谨慎放量
4)本地服务:重点管门店页、区域页和服务页
本地服务站最容易出现“城市名堆叠页”。
推荐策略
- 门店页与地址、电话、营业时间、地图、评价绑定
- 区域页必须有真实服务能力和本地化信息
- 不要把全国每个城市都做成同一模板的薄页
- 服务页与门店页保持主次关系,不要互相稀释
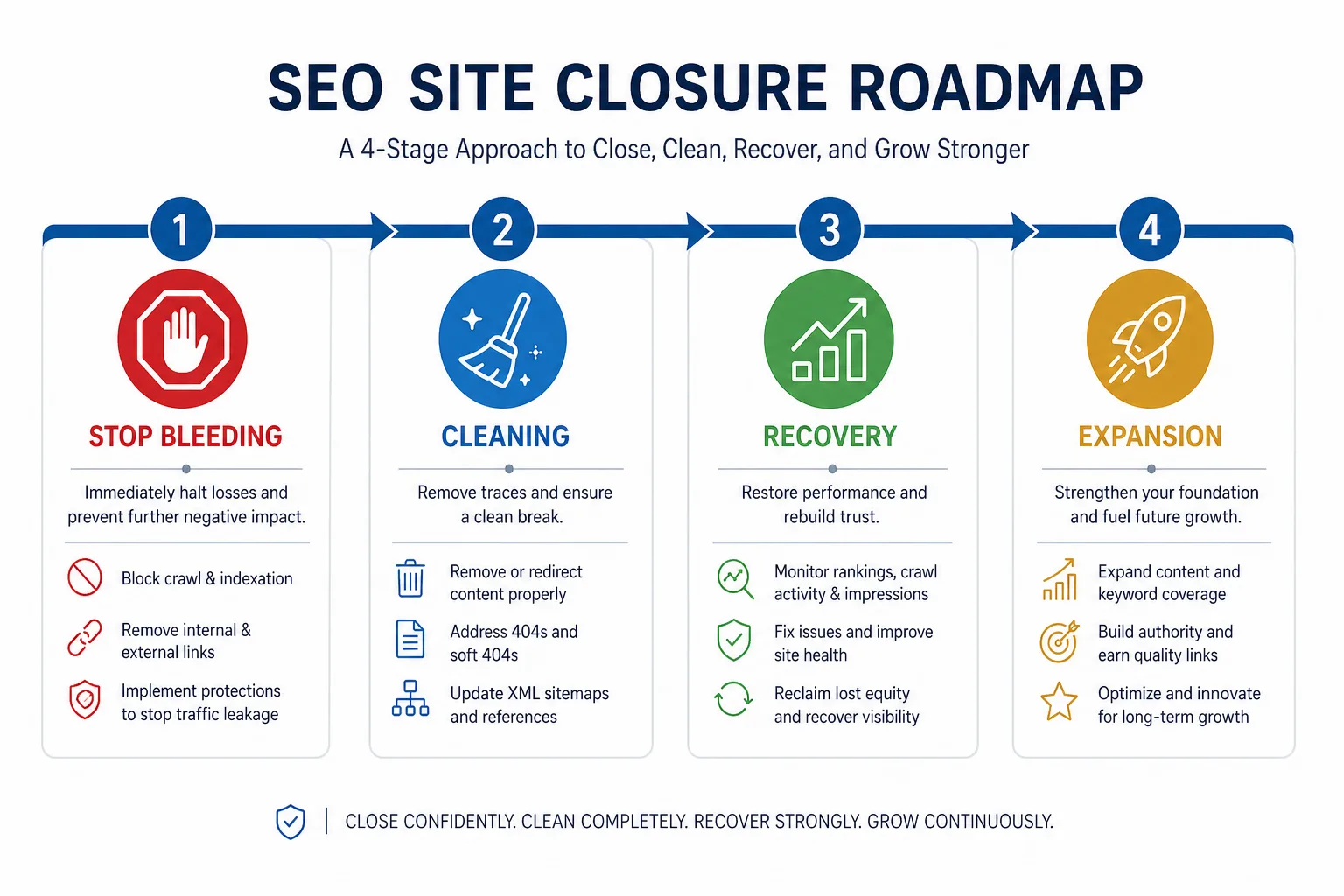
十、站点收口:先止血,再恢复,再扩张
1)收口不是一次性删页,而是分阶段治理
大站收口最怕“全站一起动”。正确顺序是:
第一阶段:止血
- 停止生成新的低价值 URL
- 阻断参数扩散
- 规范站内链接
- 修正站点地图
第二阶段:清理
- 合并重复页
- 下线无价值页
- 统一 canonical
- 对系统页、搜索页做隔离
第三阶段:恢复
- 观察抓取恢复情况
- 监测重要页面的收录和排名变化
- 复查日志,确保抓取回流到核心层
第四阶段:扩张
- 仅对验证有效的模板和页面类型扩张
- 每次新增 URL 模型前先做灰度测试
2)大站最重要的是“回滚能力”
任何批量改动都要预设回滚方案:
- canonical 改错怎么办
- robots 误封怎么办
- noindex 范围过大怎么办
- 站点地图删错主页面怎么办
- 模板合并后内容缺失怎么办
3)收口验证清单
每次收口后至少检查:
- 核心页面是否仍可正常抓取与索引
- 低价值 URL 是否真的减少进入抓取队列
- 索引构成是否逐步健康化
- 核心模板页面的流量是否稳定
- 服务器日志是否出现异常 404、5xx 或重定向链
十一、一个可执行的治理流程:从发现到收口
1)第 1 步:建立 URL 台账
把所有页面类型、目录、参数、模板、索引状态、流量、转化、抓取频率记录到表里。
2)第 2 步:按价值分层
用“搜索需求 + 商业价值 + 内容独特性 + 风险”四维判断页面去留。
3)第 3 步:识别浪费
重点排查:
- 参数页
- 分页页
- 站内搜索页
- 重复详情页
- 低质城市页
- 标签页和归档页
4)第 4 步:执行收口
组合使用:
- canonical
- noindex
- robots.txt
- 内链清理
- sitemap 精简
- 模板合并
- URL 重定向
5)第 5 步:用日志和索引数据验证
看抓取是否回流、索引是否收缩、核心页是否恢复。
十二、常见错误:很多站点不是优化失败,而是治理方向错了
1)把“索引更多”当成“效果更好”
索引量大,不代表 SEO 更强。对大站来说,健康的索引结构比单纯的索引总数更重要。
2)把参数治理只交给 robots.txt
robots 只能降低抓取概率,不能替代站内链接治理和 canonical 规范化。
3)把所有分页都 noindex
分页并不天然有问题,问题是分页是否承载独特内容和有效发现路径。
4)把城市页、行业页、标签页批量铺开
模板化扩张如果没有内容差异,只会制造规模化低质。
5)不做日志分析,只看 GSC 报表
GSC 告诉你“结果”,日志告诉你“过程”。大站治理不能只看结果。
十三、落地建议:大站 SEO 团队的组织方式
1)SEO、技术、数据要协同
大站治理不是 SEO 单兵作战,至少要形成三个角色的协作:
- SEO:定义页面优先级、收口规则、索引策略
- 技术:实现 canonical、robots、模板改造、重定向和站点地图
- 数据:监控日志、抓取、索引、流量、转化和回滚效果
2)建议建立三张常驻看板
- URL 健康看板:索引量、重复率、参数页占比、404/5xx
- 抓取看板:爬虫请求分布、抓取频率、响应时延
- 业务看板:核心页面流量、转化、排名、收录恢复情况
3)建议建立上线前审查机制
凡是会批量生成 URL 的功能,必须先过这几项:
- 是否会放大重复内容
- 是否会产生不可控参数
- 是否有索引策略
- 是否有收口回滚方案
- 是否会影响抓取预算
十四、结论:大站 SEO 的本质是“治理能力”
千万级 URL 站点的 SEO,不是“内容越多越好”,而是“结构越稳越好”。
真正有效的治理顺序是:
- 先明确 URL 分层
- 再管抓取预算
- 然后做模板收口
- 接着治理参数
- 再处理索引膨胀
- 最后用日志和优先级机制持续验证
如果你的站点已经进入规模化失控阶段,不要急着继续扩量。先把抓取浪费、索引膨胀和模板重复收口,恢复搜索引擎对站点质量的判断,再谈增长。
下一课可以继续看: