Programmatic SEO 怎么做:模板页、变量、质量边界与收录策略
Programmatic SEO 怎么做:模板页、变量、质量边界与收录策略
Programmatic SEO 的核心不是批量造页,而是把可重复的搜索意图、结构化数据和稳定的页面模板组合起来,批量生成真正有用的落地页。它适合做规模化,但不适合拿来替代编辑型内容、品牌内容和需要强专家判断的页面。
如果你现在已经做过内容集群,下一步要判断的不是“能不能做”,而是“哪些页面值得做、哪些页面必须拦住、哪些页面只允许抓取不允许收录”。这篇文章按这个顺序讲:先判断场景,再讲模板结构、变量规则、URL 设计、索引边界,最后给出行业案例和常见错误。
你可以先用这些工具做判断:
- Intent 分析工具 :看搜索意图是否稳定、是否适合模板化。
- ROI 决策工作台 :估算批量落地页的投入产出。
- AI 风险检查工具 :检查模板页是否存在同质化、低质和过度自动化风险。

一、先判断:什么情况下适合做 Programmatic SEO
适合做的场景
满足下面几条,Programmatic SEO 才值得投入:
- 搜索需求天然可拆分:同一个核心意图可以按城市、品牌、型号、行业、用途、价格区间、集成对象等维度拆成很多稳定组合。
- 每个页面都能有差异化信息:不是只替换关键词,而是可以接入不同的数据、证据、价格、库存、服务范围、案例或规则。
- 数据源稳定且可维护:你有产品库、门店库、CRM、报价表、接口文档、案例库、FAQ 库,且能定期更新。
- 商业目标明确:页面不只是为了流量,还要导向询盘、下单、试用、预约、电话、表单等转化。
- 长尾数量足够大:单页人工生产成本高,但模板化后规模收益明显。
典型适用场景:
- 电商:品牌 + 型号 + 规格 + 兼容性 + 场景。
- SaaS:集成页、用例页、替代页、行业页、功能对比页。
- B2B:行业 + 痛点 + 解决方案 + 方案包。
- 本地服务:城市 + 服务项 + 时效 + 覆盖区域 + 价格带。
不适合做的场景
以下情况不要急着上 Programmatic SEO:
- 单一搜索意图,没有足够的可拆分维度。
- 没有可靠数据源,只能靠文案拼接。
- 页面必须依赖深度编辑判断,例如品牌观点、专家解读、强合规内容。
- 每页都长得一样,只能替换城市名、产品名、行业名。
- 目标是“先把收录做大”而不是“先把页面做对”。
- 属于高风险领域,比如医疗、金融、法律等,除非有严格的专家审核和合规流程。
判断是否值得做时,先看意图,再算 ROI,再看风险:意图稳定但转化弱,通常不值得放大;意图稳定、转化明确、数据可维护,才适合规模化。
二、模板页怎么设计:先定结构,再定变量
Programmatic SEO 的模板页,最怕的不是“模板化”,而是“模板只剩皮,内容没有骨架”。一个可扩展的模板,至少要包含以下模块:
1. 标题和首屏
首屏要直接回答这个页面是谁、解决什么问题、为什么值得点进来。不要只做关键词拼接。
建议结构:
- H1:核心主题 + 变量
- 首段:一句说明适用对象和结果
- 证据块:价格、库存、案例数、服务范围、评分、对比结果等
2. 核心信息区
这里是模板页最重要的部分,必须是“变量驱动”的,而不是“换个城市名就完事”。常见模块包括:
- 规格、参数、覆盖范围、价格区间
- 对比表
- 使用场景
- 常见问题
- 真实案例或本地证据
- CTA:试用、询盘、预约、下单
3. 支撑内容区
支撑内容不是凑字数,而是给搜索引擎和用户补充差异信息:
- 不同变量对应不同规则
- 不同地区对应不同服务能力
- 不同产品对应不同兼容性
- 不同行业对应不同流程和术语
4. 内链和闭环
每个模板页都要能回到:
- 父级集合页
- 同类页面
- 相关内容页
- 转化页
没有内链闭环,批量页很容易变成孤岛页。
变量字段怎么定义
变量不是越多越好,而是越能改变搜索意图越好。建议按以下方式定义:
- 必要变量:决定页面主题和意图,例如城市、服务、型号、行业、集成对象。
- 证明变量:决定页面是否可信,例如门店数、库存数、案例数、评分、交付周期。
- 限制变量:决定页面是否可展示,例如是否有库存、是否覆盖该区域、是否支持该接口。
- 时间变量:决定页面是否过期,例如 last_updated、price_updated、stock_updated。
原则很简单:
1. 变量必须影响用户决策。
2. 变量必须来自真实数据源。
3. 变量必须可校验、可更新、可追踪。
数据源怎么选
Programmatic SEO 失败,很多时候不是模板写错,而是数据源不对。数据源优先级建议如下:
- 第一方数据:产品库、订单库、CRM、工单库、门店库、库存库。
- 业务系统数据:报价表、服务范围、案例库、知识库、接口文档。
- 公开数据:地图、行业目录、统计数据、政策数据。
- 人工维护数据:适合少量高价值页面,不适合全量批量页。
数据源一定要做三件事:
- 去重
- 归一化
- 设置缺省值和异常值
示例 1:页面生成配置
下面这个配置的作用,是把“能不能生成、能不能收录”从主观判断变成规则判断。
page_type: city_service
slug_template: '/services/{city_slug}/{service_slug}/'
required_fields:
- city_name
- city_slug
- service_name
- local_price_range
- local_proof
- faq
- canonical_url
quality_rules:
min_unique_fields: 4
min_body_chars: 800
require_internal_links: true
index_rules:
index_when:
- demand_score >= 30
- content_score >= 80
- local_proof == true
otherwise: noindex
这段配置解决三个问题:
- 生成控制:缺字段就不生成,避免空页。
- 质量控制:长度、独特字段、内链都达标才允许上线。
- 索引控制:不满足条件的页面默认 noindex,避免低质页进入索引池。
URL 设计怎么做
URL 的目标不是炫技,而是稳定、可读、可维护。
推荐原则:
- 一页一个主意图
- 层级表达清楚
- 尽量短且可预测
- 避免无意义参数堆叠
- 过滤页、排序页、临时页不要直接进入主索引结构
常见结构示例:
- 电商:/products/{brand}/{model}/
- SaaS:/integrations/{tool}/、/use-cases/{industry}/
- B2B:/solutions/{industry}/{problem}/
- 本地服务:/services/{city}/{service}/
不要把所有维度都塞进 URL。URL 过长会导致管理混乱,也会让同一意图产生过多变体。

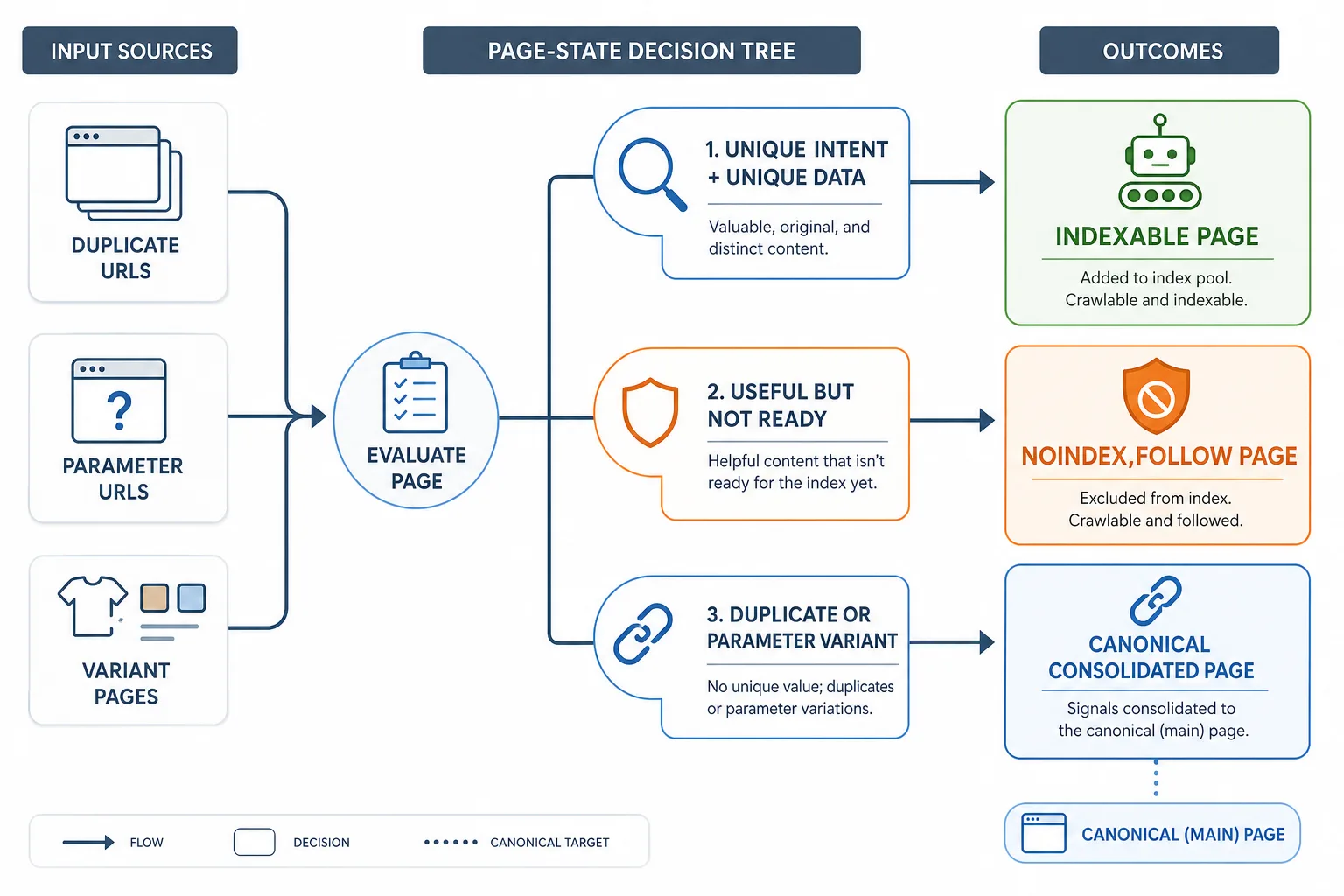
三、索引边界怎么定:canonical、noindex 和索引池
Programmatic SEO 最重要的不是“生成多少页”,而是“哪些页允许进入索引”。这里建议把页面分成三类:
1. 可索引页
满足以下条件才允许索引:
- 意图明确
- 内容有差异
- 数据真实
- 有转化目标
- 有内链支持
2. 只抓取不索引页
适合这些情况:
- 页面有用户价值,但暂时还不够独特
- 需要先观察行为数据,再决定是否放开索引
- 作为实验页、灰度页、候选页存在
这类页面建议使用 noindex,follow。
Google 对 noindex 的说明可以参考 Google Search Central 的 noindex 文档。
3. 归并页、重复页和参数页
适合这些情况:
- 排序、筛选、分页、参数组合导致的重复内容
- 同一内容有多个可访问 URL
- 页面主体一致,只有少量变量不同
这类页面用 canonical 归并,不要靠首页兜底,不要把所有变体都指向首页。
Google 对 canonical 的说明可以参考 Google Search Central 的 canonical 说明。
示例 2:canonical 和 noindex 的模板控制
下面这段代码的作用,是让模板页在不同状态下自动决定是否进入索引。
<head>
<link rel='canonical' href='https://example.com/services/shanghai/pest-control/' />
{% if page.indexable %}
<meta name='robots' content='index,follow' />
{% else %}
<meta name='robots' content='noindex,follow' />
{% endif %}
</head>
这段代码解决的问题是:
- 重复内容合并:通过 canonical 指向主版本,减少重复收录。
- 质量边界控制:低质量或未验证页面先 noindex,避免污染索引。
- 发布节奏控制:页面可以先上线给用户看,再根据表现决定是否放开索引。
一个实用的索引边界规则
你可以直接按下面三档执行:
- 索引:有独立意图、有独特数据、有转化动作。
- noindex:有一定价值,但信息不足、数据不全、还在实验。
- 不生成或归并:只是关键词变体、排序变体、重复内容。
注意:robots.txt 不是索引控制工具。它只能限制抓取,不等于删除索引。需要控制收录时,优先考虑 canonical 和 noindex,而不是直接封抓。
四、质量边界怎么设:不是所有可生成的页都值得上线
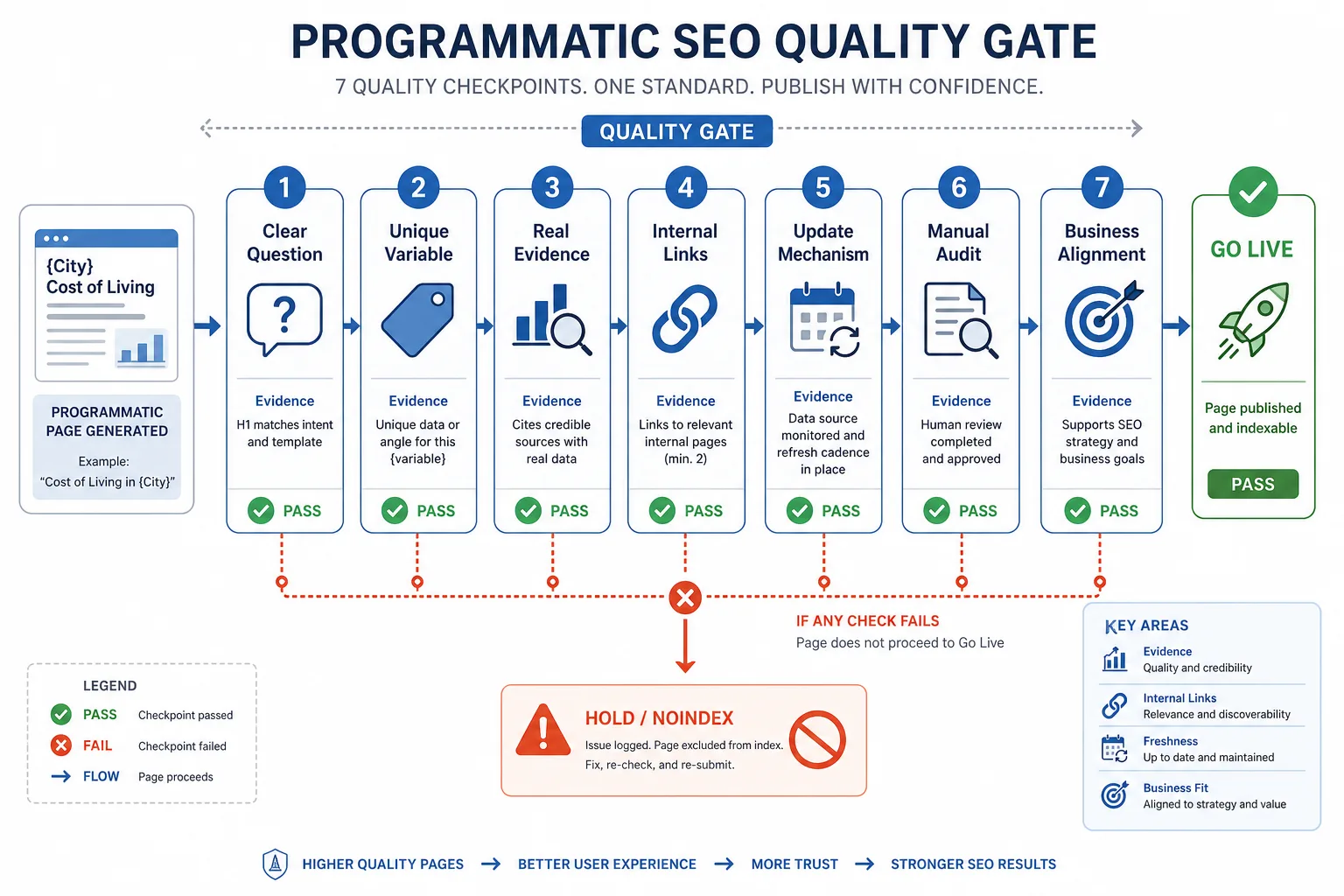
Programmatic SEO 的质量边界,建议至少设 7 条线:
1. 页面必须回答一个明确问题
比如:
- 这个城市能不能服务?
- 这个型号是否兼容?
- 这个行业有没有对应方案?
- 这个工具能否和某产品集成?
2. 页面必须包含至少一组独特变量
仅替换关键词不算独特。至少要有:
- 本地数据
- 价格/库存/服务范围
- 案例/评分/交付时间
- 行业规则或适配条件
3. 页面必须有真实证据
证据可以是:
- 实时价格
- 库存状态
- 门店地址
- 客户案例
- API 文档
- 使用说明
4. 页面必须有内链
至少链接到:
- 同类页
- 上级集合页
- 转化页
- 帮助页或 FAQ 页
5. 页面必须有更新机制
如果数据会变,就要有更新时间、版本号或刷新策略。否则批量页很容易因为过期而失真。
6. 页面必须能被人工抽检
建议每批上线前做抽检,重点看:
- 标题是否唯一
- 首屏是否有信息量
- 变量是否真实
- canonical 是否正确
- noindex 是否按规则生效
7. 页面必须和业务目标一致
如果页面没有转化路径,只能带来零散流量,那它通常不值得批量扩张。
你也可以用 AI 风险检查工具 来审查批量页是否出现“模板味太重、语义重复、信息空洞”的问题。
五、行业案例:电商、SaaS、B2B、本地服务怎么落地
电商:品牌、型号、规格、兼容性页
适合做的页面:
- 品牌 + 型号 + 配件兼容页
- 型号 + 颜色 + 尺寸页
- 场景 + 商品组合页
可用变量:
- 商品名、品牌、型号、库存、价格、评分、兼容设备、配送时效
质量边界:
- 只有在库存、价格、评价、兼容关系清晰时才可索引。
- 没有真实库存和评价的组合页,先 noindex。
常见落地页示例:
- iPhone 15 兼容磁吸手机壳
- 适用于 MacBook Air 的 65W 充电器
- 厨房用不锈钢收纳架
SaaS:集成页、用例页、替代页
适合做的页面:
- A 工具 + B 工具 的集成页
- 某行业的 use case 页
- 替代竞品页
- 功能对比页
可用变量:
- 集成对象、行业、使用场景、功能模块、操作步骤、案例、文档链接
质量边界:
- 不能只是把工具名替换掉。
- 必须写出真实流程、触发条件、限制事项和操作路径。
例子:
- Notion + Slack 集成
- 适合制造业的工单自动化
- CRM 替代电子表格的迁移方案
B2B:行业页、解决方案页、问题页
适合做的页面:
- 行业 + 痛点 + 方案
- 岗位 + 任务 + 工具
- 场景 + 结果 + 证据
可用变量:
- 行业、岗位、使用场景、决策流程、案例、ROI、交付周期
质量边界:
- 必须有行业术语和真实业务流程。
- 必须有案例、流程图、实施步骤或结果数据。
例子:
- 制造业线索分配自动化
- 采购审批流程优化方案
- 销售团队线索评分模型
本地服务:城市页、服务范围页、门店页
适合做的页面:
- 城市 + 服务项
- 区域 + 紧急服务
- 门店 + 服务能力
可用变量:
- 城市名、区域名、服务半径、门店地址、服务时间、报价区间、客户评价
质量边界:
- 必须有本地证据,例如门店地址、服务范围、实际案例、当地电话。
- 不要给每个城市一模一样的介绍页。
例子:
- 上海 24 小时管道疏通
- 深圳 企业保洁服务
- 北京 家电上门维修
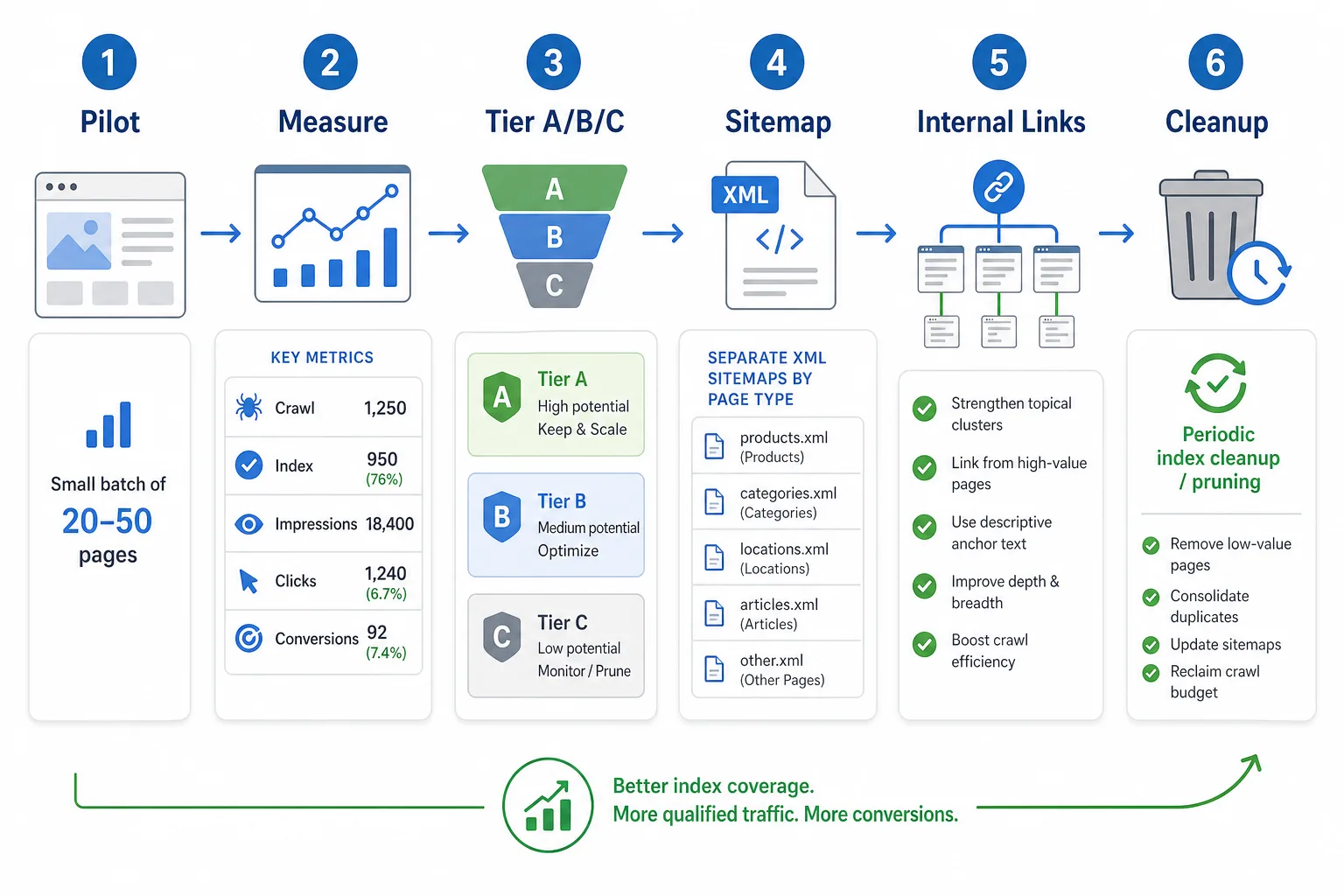
六、收录策略:先小范围验证,再决定放量
Programmatic SEO 不应该一口气把全量页放出去,正确做法是分阶段收录。
第一步:先做试点页
建议先放 20 到 50 个页面,观察:
- 是否被抓取
- 是否进入索引
- 是否有展示
- 是否有点击
- 是否有停留和转化
第二步:按表现分层
可以把页面分成三层:
- A 层:有曝光、有点击、有转化,继续放大。
- B 层:有曝光但点击弱,优化标题、摘要和首屏。
- C 层:无展示、无价值、同质化严重,noindex 或合并。
第三步:按页面类型提交 sitemap
把不同类型页面拆成不同 sitemap,方便监控和排查。Google 对 sitemap 的说明可以参考 Google Search Central 的 Sitemap 指南。
第四步:用内链推动收录
优先从这些位置给新页入口:
- 集合页
- 类别页
- 相关 FAQ
- 推荐模块
- 地区导航页
第五步:定期做索引清理
每 30 天检查一次:
- 是否有大量重复页被收录
- 是否有低质页抢占抓取预算
- 是否有页面需要从 index 改为 noindex
- 是否有页面需要 canonical 归并
七、常见错误:很多团队就是在这里把项目做废了
错误 1:只换关键词,不换信息
城市页只换城市名,商品页只换型号名,行业页只换行业名。这类页面通常没有独立价值。
错误 2:URL 变体太多
同一个意图有多个路径、多个参数、多个排序版本,最后导致重复收录和权重分散。
错误 3:所有页面都指向首页 canonical
这会让搜索引擎看不懂页面关系。canonical 应该指向最接近的主版本,而不是粗暴统一到首页。
错误 4:先批量上线,再想质量
正确顺序是:先定义质量门槛,再批量生成,再抽检上线。
错误 5:只看收录,不看转化
Programmatic SEO 的目标不是收录量最大化,而是有效页面数量最大化。
错误 6:把 robots.txt 当 noindex 用
robots.txt 只能影响抓取,不等于控制索引。需要控制收录时,优先用 canonical 和 meta robots。
错误 7:不做数据治理
变量源脏了,页面就会批量错误。比如库存过期、门店地址错、服务范围变更、案例失效。
八、落地顺序:先解决结构,再解决规模
如果你今天就要启动,可以按这个顺序做:
- 选 1 个高意图页面类型,不要一开始就全行业铺开。
- 定义模板结构,先定模块,再定文案。
- 定义变量清单和数据源,每个变量都要能回溯来源。
- 设索引规则,先可抓取,再决定是否索引。
- 设质量门槛,抽检通过再放量。
- 用 sitemap 和内链推动收录。
- 按数据结果迭代,保留能转化的页,淘汰低质页。
如果你把 Programmatic SEO 当成“自动批量写页”,大概率会做出一堆门页;如果你把它当成“用结构化数据放大高意图页面”,它才会成为规模化获客工具。关键不在于生成速度,而在于模板、变量、索引边界和质量门槛是否同时成立。
下一课可以继续看: