SEO 面包屑与站点层级怎么做:分类树、URL 树与主题树统一方法
SEO 面包屑与站点层级怎么做:分类树、URL 树与主题树统一方法
站点层级不是单纯的栏目设计,它决定了搜索引擎如何理解你的网站:哪些页面是目录,哪些页面是正文,哪些页面只是筛选结果,哪些页面应该继承权重。真正可落地的做法,不是只画一张分类树,而是把分类树、URL 树、主题树统一到同一套页面职责中,并用面包屑、内链和结构化数据把这套职责讲给搜索引擎听。
如果你正在重做信息架构,建议先用 意图分析工具 把搜索词按任务、场景和问题分组,再决定目录层级;如果你需要给改版排序,可以用 SEO ROI 决策工作台 先判断哪些层级最值得迁移;如果要评估批量改写内容的风险,可用 AI 风险检测 做前置审查。
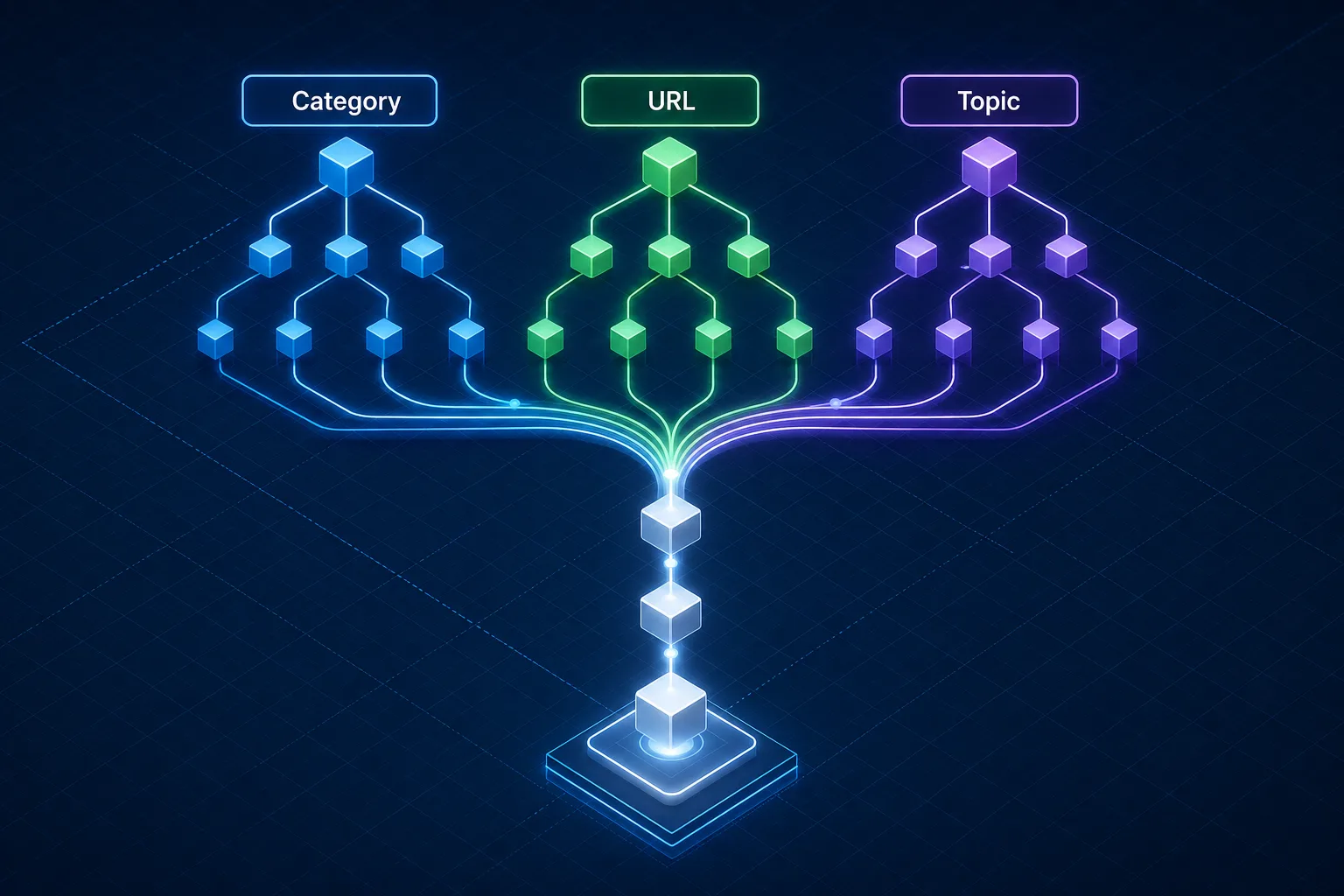
先搞清三棵树分别负责什么
分类树:给运营和内容管理用
分类树解决的是“内容怎么归类、谁负责、放哪里”。它偏业务管理,常见于电商类目、内容频道、知识库目录、产品手册目录。
分类树的目标不是取悦搜索引擎,而是让团队有稳定的内容归属。
URL 树:给爬虫路径和索引控制用
URL 树解决的是“页面之间怎么走、权重怎么传、哪些页允许被索引”。它必须稳定、可预测、可重定向。
一个清晰的 URL 树应当让爬虫从首页一路走到核心内容页,不依赖搜索框、不依赖 JS 动态筛选,也不让参数页污染主层级。
主题树:给搜索意图和专题覆盖用
主题树解决的是“用户为什么搜、哪些页面一起覆盖一个主题、主文和辅文如何分工”。它更接近语义聚类和搜索意图。
例如“CRM”不是一个目录名那么简单,它可能同时覆盖:
- CRM 是什么
- CRM 功能
- CRM 行业方案
- CRM 价格
- CRM 对比
这些内容在主题树里是一组,在分类树里未必是同一层,在 URL 树里也未必相邻。
三棵树的统一原则
| 维度 | 分类树 | URL 树 | 主题树 |
|---|---|---|---|
| 主要职责 | 内容管理 | 爬虫路径与索引 | 搜索意图覆盖 |
| 变化频率 | 中高 | 低 | 中高 |
| 设计依据 | 业务组织 | 技术可维护性 | 关键词与任务 |
| 是否必须一致 | 不必完全一致 | 必须稳定 | 必须与主页面匹配 |
统一方法只有一句话:一个页面只认一个主父级、一个主 URL、一条主面包屑、一套主内链路径。
这不是限制,而是为了减少歧义。搜索引擎最怕的不是页面少,而是页面身份不清。
先看官方口径
Google 对面包屑结构化数据的说明见:
- https://developers.google.com/search/docs/appearance/structured-data/breadcrumb?hl=zh-cn
- https://developers.google.com/search/docs/fundamentals/seo-starter-guide?hl=zh-cn
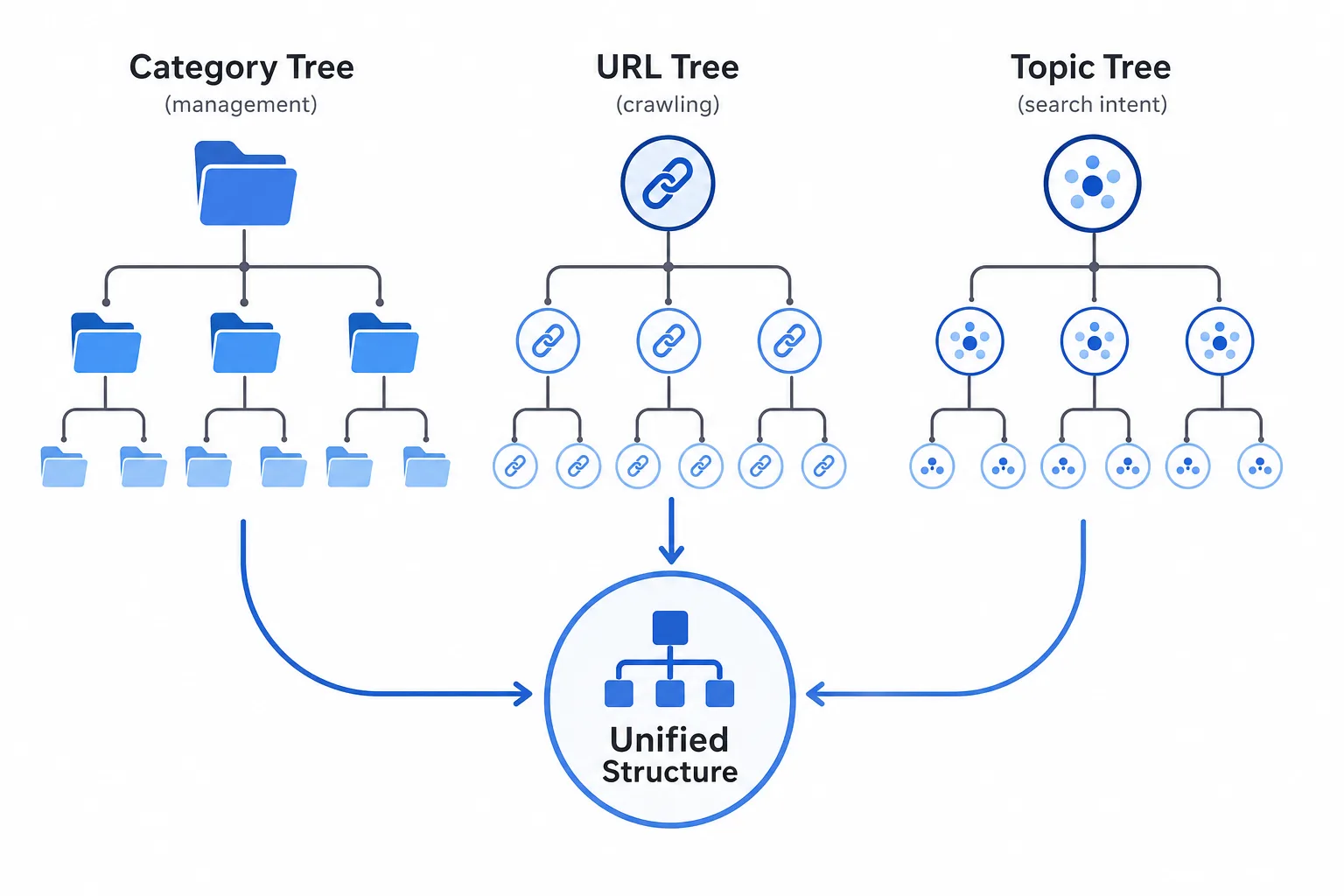
站点层级设计要先定义页面职责
第一步:先分页面类型,再分栏目
不要先画栏目树,再找页面塞进去。正确顺序是:
- 先定义页面职责:列表页、专题页、详情页、落地页、筛选页、搜索结果页。
- 再定义每种页面的索引策略:可索引、条件索引、不可索引。
- 再把页面映射到分类树、URL 树和主题树。
页面职责示例
| 页面类型 | 职责 | 索引建议 | 是否进入主层级 |
|---|---|---|---|
| 首页 | 总入口 | 可索引 | 是 |
| 类目页 | 聚合内容与传递权重 | 可索引 | 是 |
| 专题页 | 主题覆盖与深度解释 | 可索引 | 是 |
| 内容详情页 | 解决具体问题 | 可索引 | 是 |
| 筛选页 | 长尾组合检索 | 多数不索引 | 否 |
| 搜索结果页 | 站内检索结果 | 通常不索引 | 否 |
| 标签页 | 弱聚合 | 视情况而定 | 谨慎 |
第二步:确定层级粒度
层级不是越深越好,也不是越浅越好。原则是:
- 首层放战略类目或核心场景
- 二层放可被搜索的聚合页
- 三层放高价值详情页
- 再往下的层级尽量控制在必要范围内
如果一个详情页必须经过四层以上才能到达,说明层级设计已经偏深,搜索和用户都会吃亏。
第三步:把职责绑定到 URL、面包屑和 Schema
每一页都要回答三个问题:
- 我属于哪个主层级
- 我从哪里来
- 我在整个站点体系中扮演什么角色
这三个答案必须在 URL、面包屑、内链和结构化数据中保持一致。
面包屑设计不是装饰,而是层级声明
设计原则
面包屑的作用不是好看,而是声明路径。
建议遵循以下规则:
- 从首页开始,逐级展示到当前页
- 只展示主路径,不展示所有可能路径
- 当前页不设链接,父级页保留可点击
- 面包屑文本与栏目命名、URL slug 尽量一致
- 多分类页面只保留一个主面包屑
多归属页面怎么选主路径
有些页面天然属于多个目录,例如一篇内容既可放在“AI”,也可放在“产品效率”。这时不要同时输出两条面包屑,而是按以下顺序决定主路径:
- 看主搜索意图归属
- 看该页最能传递权重的父级
- 看该页是否有稳定的 canonical URL
- 看该页是否会长期被内容团队维护
选定主路径后,其他路径可以用相关推荐、专题入口或标签页承接,不要抢主层级。
BreadcrumbList Schema 示例
下面是可直接复制的 HTML + JSON-LD 示例。它把可见面包屑和结构化数据统一起来,适合详情页、专题页、产品页使用。
<nav aria-label="breadcrumb">
<ol>
<li><a href="https://www.example.com/">首页</a></li>
<li><a href="https://www.example.com/solutions/">解决方案</a></li>
<li><a href="https://www.example.com/solutions/crm/">CRM</a></li>
<li aria-current="page">客户分层管理</li>
</ol>
</nav>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "首页",
"item": "https://www.example.com/"
},
{
"@type": "ListItem",
"position": 2,
"name": "解决方案",
"item": "https://www.example.com/solutions/"
},
{
"@type": "ListItem",
"position": 3,
"name": "CRM",
"item": "https://www.example.com/solutions/crm/"
},
{
"@type": "ListItem",
"position": 4,
"name": "客户分层管理",
"item": "https://www.example.com/solutions/crm/customer-segmentation/"
}
]
}
</script>
这个示例的作用有三点:
- 告诉搜索引擎当前页在站点中的位置
- 明确父子关系,减少层级歧义
- 在搜索结果中更稳定地展示路径信息
面包屑与 canonical 必须一致
如果页面的主 canonical 是 https://www.example.com/solutions/crm/customer-segmentation/,那么面包屑、站内链接、站点地图里的主路径也应该围绕这条 URL 展开。不要让 canonical 指向一个路径,面包屑却显示另一条路径。
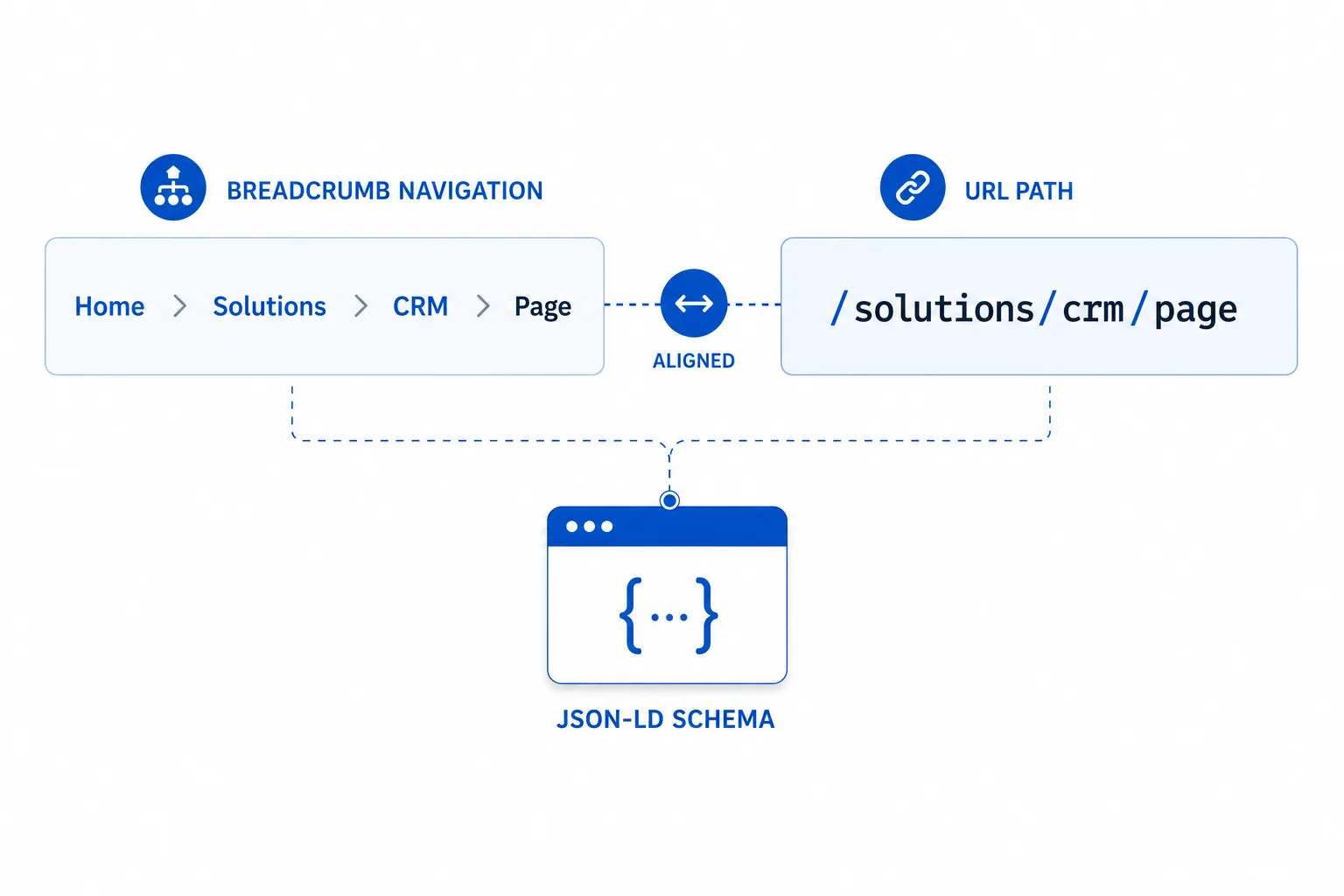
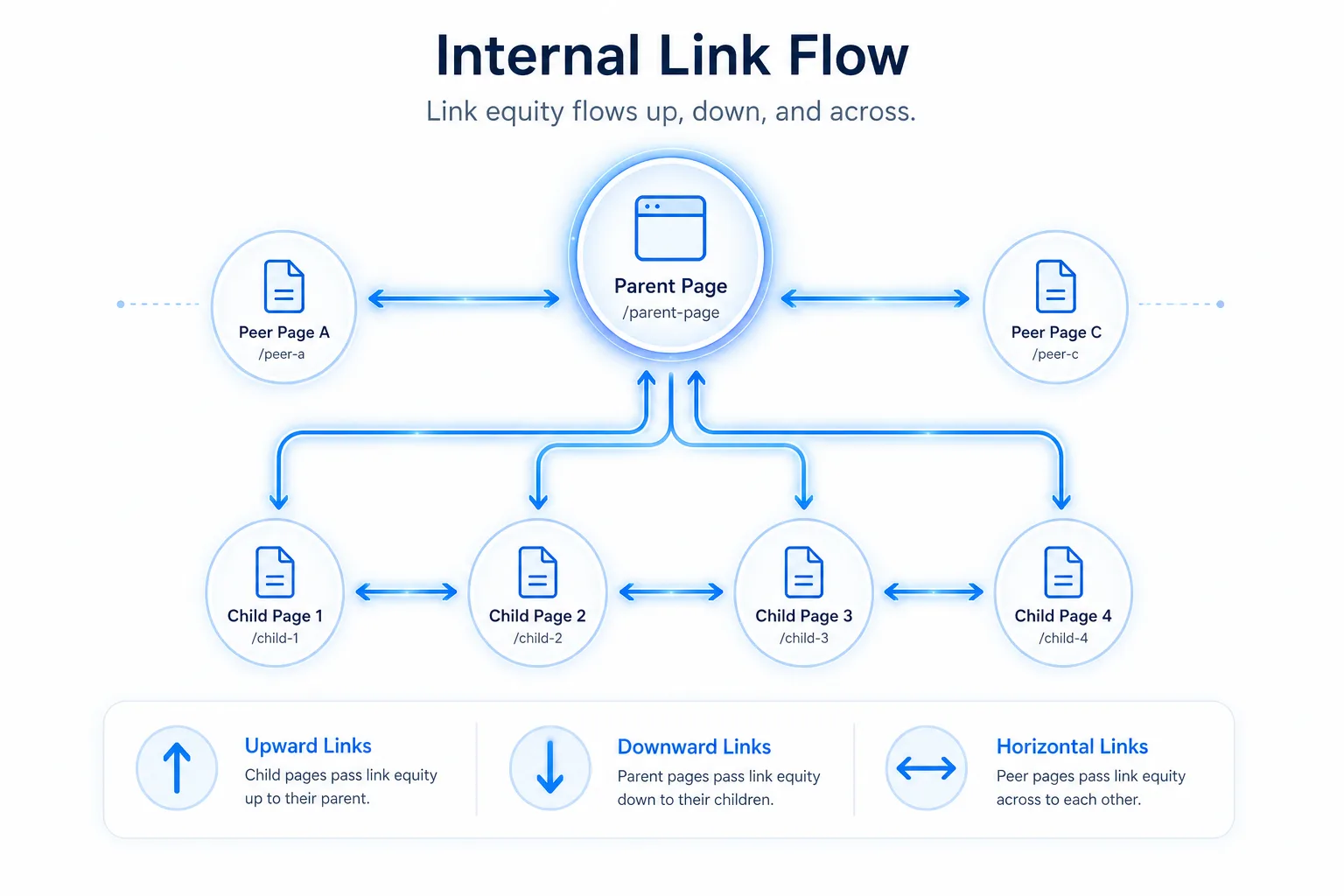
内链路径要让权重沿着主层级流动
内链不是越多越好,而是路径要对
内链的目标不是堆数量,而是让爬虫顺着你的层级逻辑走到核心页面。
建议把内链分成三类:
- 上行链接:从详情页回到父级页
- 横向链接:同层级页面互相推荐
- 下行链接:类目页、专题页指向核心内容页
锚文本要表达页面职责
锚文本不要只写“点击这里”,而要写清楚页面任务。例如:
- CRM 功能总览
- 客户分层管理方案
- 上海家政服务报价
- 工业设备维保案例
锚文本与面包屑、标题、H1 不必完全一致,但语义必须一致,不能互相打架。
内链路径的最低标准
- 核心类目页至少能链接到所有关键子页
- 关键子页能回链父级专题页
- 同主题页面之间保留少量强相关链接
- 不把随机标签页当主导航
行业案例:四种常见站点怎么统一
电商:类目树是主骨架,属性筛选不能抢层级
电商最常见的问题是把品牌、属性、价格筛选全部做成可索引层级,最后 URL 数量爆炸。
建议做法:
- 分类树:一级类目 > 二级类目 > 品类
- URL 树:保持固定类目路径,例如
/electronics/laptops/gaming/ - 主题树:围绕购买意图组织内容,如选购指南、对比、评测、常见问题
- 面包屑:只保留主类目路径,不展示所有筛选条件
示例:
- 首页 > 电脑 > 游戏本 > 某款机型
- 首页 > 家居 > 收纳 > 衣柜整理盒
筛选页如果只是参数组合,通常不应成为主索引页。
SaaS:功能树、场景树和行业树要分开
SaaS 很容易把功能、场景、行业混成一棵树,导致首页导航复杂、专题页重复。
建议拆成三层:
- 功能树:权限、报表、自动化、审计
- 场景树:销售管理、客户运营、审批流
- 行业树:零售、教育、制造、物流
URL 树可以稳定成:
- /features/automation/
- /solutions/sales/
- /industries/manufacturing/
主题树则按意图组织:
- CRM 是什么
- 如何提升销售转化
- 制造业如何做客户分层
B2B:产品线、行业方案、案例中心要明确分工
B2B 网站常见的错误是把所有内容都挂在“解决方案”下面。
建议:
- 产品线页负责介绍产品能力
- 行业方案页负责说明场景适配
- 案例页负责证明效果
- 资源中心负责覆盖认知和比较型搜索
例如:
- 首页 > 产品 > 工业视觉检测系统 > 软件平台
- 首页 > 解决方案 > 汽车零部件 > 质量检测
- 首页 > 案例 > 华东某工厂 > 降低漏检率
本地服务:城市树要服务转化,不要无限分叉
本地服务网站最容易把城市、区域、门店、服务项做成无限分叉,最后既难维护,也不利于索引。
建议:
- 城市页做主入口
- 区域页只保留高价值区域
- 服务页承接具体业务需求
- 门店页用于本地转化
示例:
- 首页 > 上海家政 > 深度保洁
- 首页 > 深圳搬家 > 跨城搬家
- 首页 > 北京开锁 > 朝阳区开锁
如果一个地区没有真实业务或内容供给,不要为了层级而层级。
站点改版与层级迁移怎么做
先做映射表,再动 URL
改版时最危险的不是页面换皮,而是旧层级信号被切断。正确顺序是先做映射表,再上线新结构。
下面这个 YAML 示例可以作为迁移对照表:
migration_map:
- old_url: /category/phones/android/
new_url: /products/android-phones/
status: 301
breadcrumb: 首页 > 手机 > Android手机
- old_url: /solutions/legacy-crm/
new_url: /solutions/crm/
status: 301
breadcrumb: 首页 > 解决方案 > CRM
- old_url: /service/cleaning/shanghai/
new_url: /services/shanghai/deep-cleaning/
status: 301
breadcrumb: 首页 > 上海家政 > 深度保洁
这个示例的作用是:
- 把旧 URL 和新 URL 一一对应
- 确保 301 跳转可批量执行
- 保证旧层级信号能顺利迁移到新层级
改版迁移的执行顺序
- 先冻结旧站层级,禁止临时增删目录
- 产出旧 URL 到新 URL 的映射表
- 确认 canonical、面包屑、站点地图同步更新
- 批量上线 301 重定向
- 用日志和抓取报告检查是否还有旧 URL 被访问
- 观察核心页收录、排名和流量恢复情况
索引控制别忽略这些细节
- 参数页、过滤页、搜索结果页通常不进入主索引
- 重复聚合页要用 canonical 指向主页
- 已废弃层级要 301,不要直接 404
- 旧面包屑文本要与新面包屑语义对齐
- 站点地图只保留你愿意被索引的主路径
改版后如何判断是否迁移成功
重点看三类信号:
- 抓取是否集中到新 URL
- 收录是否由旧层级转向新层级
- 核心词是否仍然落在目标页面上
如果你发现搜索引擎还在把旧分类页当主结果,说明你的重定向、内链或面包屑还没有完全统一。
长期维护:把层级治理做成机制,而不是一次项目
建一个层级责任表
建议由 SEO、产品、内容、前端共同维护一张层级责任表,至少包含:
- 页面名称
- 页面类型
- 主父级
- 主 URL
- 是否可索引
- 面包屑路径
- 负责团队
- 最后更新时间
每月做一次层级审计
审计重点看四件事:
- 新增页面有没有跑偏到错误层级
- 旧页面是否产生重复层级
- 面包屑和 URL 是否一致
- 主题树是否被无意义标签稀释
如果你想把审计优先级排得更合理,可以借助 SEO ROI 决策工作台 先判断哪些层级最影响收入,再决定先修哪里。
用 AI 但别让 AI 破坏层级
AI 生成内容很容易把主题写散、标题写乱、目录拆得过深。上线前建议用 AI 风险检测 先看是否出现:
- 主题漂移
- 标题与页面职责不一致
- 同一关键词被多个页面争抢
- 新增内容破坏已有分类树
最后记住这条原则
站点层级的本质不是“分多少层”,而是“每一层是否有明确职责”。
只要你把分类树、URL 树和主题树统一到同一套页面职责里,再配合面包屑、BreadcrumbList Schema、内链路径和迁移映射表,搜索引擎就更容易理解你的网站,长期维护成本也会明显下降。
下一课可以继续看: