SEO 参数页怎么治理:排序、分页、会话参数与抓取预算
SEO 参数页怎么治理:排序、分页、会话参数与抓取预算
参数页不是天然的 SEO 问题,问题在于:它会不会制造重复 URL、消耗抓取预算、稀释内链权重,最终让规范页更难被发现。治理参数页,核心不是一刀切禁抓,而是先判断参数类型,再决定是保留、规范化,还是直接收口。
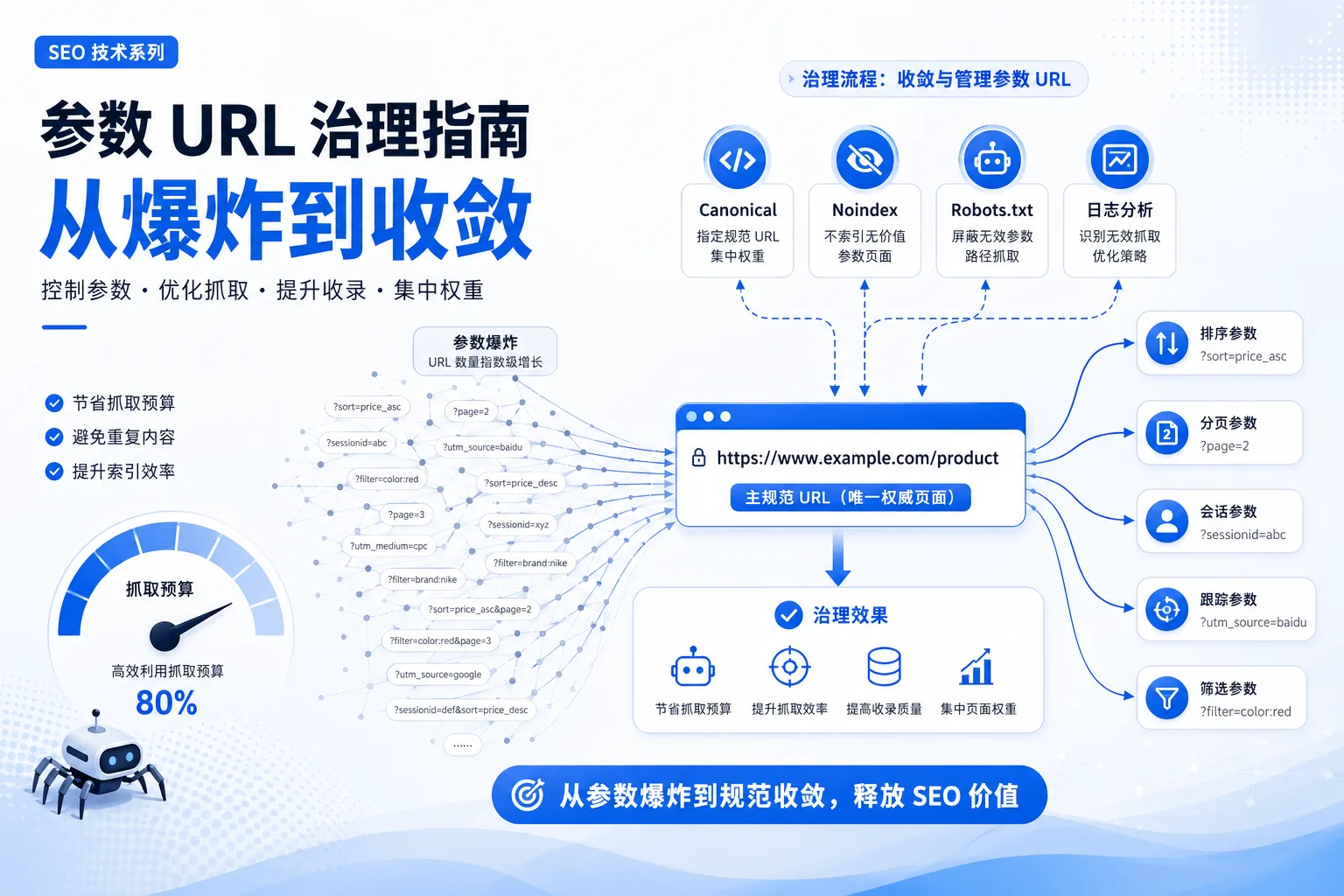
先给参数分类:哪些必须收口,哪些必须保留
| 参数类型 | 典型示例 | 默认策略 | 只有在以下情况才保留 |
|---|---|---|---|
| 排序参数 | sort=price、sort=new | canonical 到主列表页;内部链接只保留一个默认排序 | 排序本身有搜索意图,如 best-selling |
| 分页参数 | page=2、page=3 | 保留抓取、self canonical、可索引 | 只有极薄、无独立价值的分页才考虑 noindex |
| 会话参数 | sessionid、jsessionid、sid | 彻底收口,优先改成 Cookie | 基本不保留 |
| 跟踪参数 | utm_source、gclid、fbclid | 内链不带参,落地后归一化 | 仅用于广告归因的入口链路 |
| 筛选参数 | color=red、brand=nike、price=100-200 | 白名单 + 归一化;大部分组合 noindex | 有明确搜索需求且内容充足 |
排序参数
排序只改变展示顺序,不改变内容集合时,通常不该单独形成可索引页面。典型场景是电商商品列表的 price、new、rating 排序,或者内容平台的 newest、popular 排序。默认做法是:排序参数页面保留给用户用,但搜索引擎侧尽量合并到主列表页,避免把同一批内容拆成大量近似页。
如果某个排序组合本身有真实搜索意图,比如 best-selling、most-reviewed、popular cars 这类商业词,可以单独评估是否做成静态落地页,而不是依赖 ?sort= 参数页。判断标准不是能不能收录,而是这个页面是否比主列表页更能满足查询意图。不确定时,可以先用 意图识别工具 看搜索意图,再用 ROI 决策工作台 判断是否值得承担索引成本。
分页参数
分页不是天然重复。只要每一页都承载不同内容集合,分页页就应该保留抓取信号,通常使用 self canonical,而不是全部归并到第一页。电商分类页、内容列表页、产品列表页,页面 2、3、4 的商品或文章集合都不同,搜索引擎需要能抓到这些页面,才能发现更深层内容。
错误做法是把 page=2、page=3 全部 canonical 到 page=1,或者直接给分页页 noindex。这样做的结果往往不是省预算,而是切断发现路径。如果分页页确实极薄、价值很低,才考虑 noindex,follow;但对大多数列表型页面,尤其是商品库和内容库,分页应该默认可抓可索引。
会话参数
会话参数是最典型的治理对象。sessionid、jsessionid、sid 这类参数通常只服务于状态维持,不承载独立搜索价值,却最容易制造重复 URL。治理原则很简单:不要让会话出现在可索引 URL 里。
优先级从高到低是:
1. 用 Cookie 替代 URL 会话。
2. 站内链接统一输出干净 URL。
3. 已产生的会话参数 URL 做 301 归一化到规范页。
4. 如果历史包袱太重,至少确保它们不进入 sitemap,也不被内部链接反复放大。
跟踪参数
utm_source、utm_medium、utm_campaign、gclid、fbclid 这类参数,通常只用于归因分析,不应该成为搜索引擎看到的独立页面。最有效的做法是:站内链接永远不要带跟踪参数;落地页收到跟踪参数后,尽快归一化到干净 URL。
注意一个常见误区:跟踪参数页不要靠 robots.txt 一禁了之。如果你还希望搜索引擎看到 canonical 或 noindex,页面就必须能被抓取。robots.txt 适合阻止纯噪音抓取,不适合替代索引控制。
筛选参数
筛选参数最容易把网站推入参数爆炸。颜色、品牌、价格区间、地区、容量、属性、标签,只要组合一多,URL 数量就会指数上升。筛选参数的治理必须先做白名单:哪些组合有搜索需求,哪些只是站内交互。
一般规则是:
- 有真实搜索需求、内容充足、能形成稳定落地页的组合,可以保留并单独设计静态 URL。
- 只是帮助用户缩小范围、但没有独立搜索意图的组合,应该 canonical 到主类目页,必要时配合 noindex,follow。
- 永远不要让所有筛选组合自由组合地被搜索引擎探索,否则抓取预算会被无效组合吞掉。
抓取预算与参数爆炸:为什么参数页会拖慢收录
抓取预算不是抽象概念,而是搜索引擎在你站点上愿意分配的抓取资源。对中大型电商、内容库、SaaS 帮助中心、B2B 目录站、本地服务聚合站来说,参数爆炸会直接把预算从新内容和更新内容上,挪到重复组合上。
一个简单例子:
- 3 种排序
- 5 个分页
- 8 个筛选值
- 2 个会话或跟踪变体
组合起来就是 3 × 5 × 8 × 2 = 240 个 URL 变体。
如果再叠加第二个筛选维度,数量会继续乘上去,而不是相加。站点越大,这种乘法越可怕。
参数爆炸的直接后果通常有四个:
1. 抓取请求大量落在重复页面上。
2. 重要规范页更新变慢。
3. 索引库里出现大量近似页,稀释排名信号。
4. 日志里 bot 命中很多,但有效抓取很少。
你应该优先看这些日志指标:
- 参数 URL 的抓取占比是否持续上升。
- 200 响应里,重复页是否占多数。
- 规范页的抓取频率是否被挤压。
- 爬虫是否反复进入低价值分页、低价值筛选和会话页。
- 3xx 链是否过长,是否存在参数跳转链。
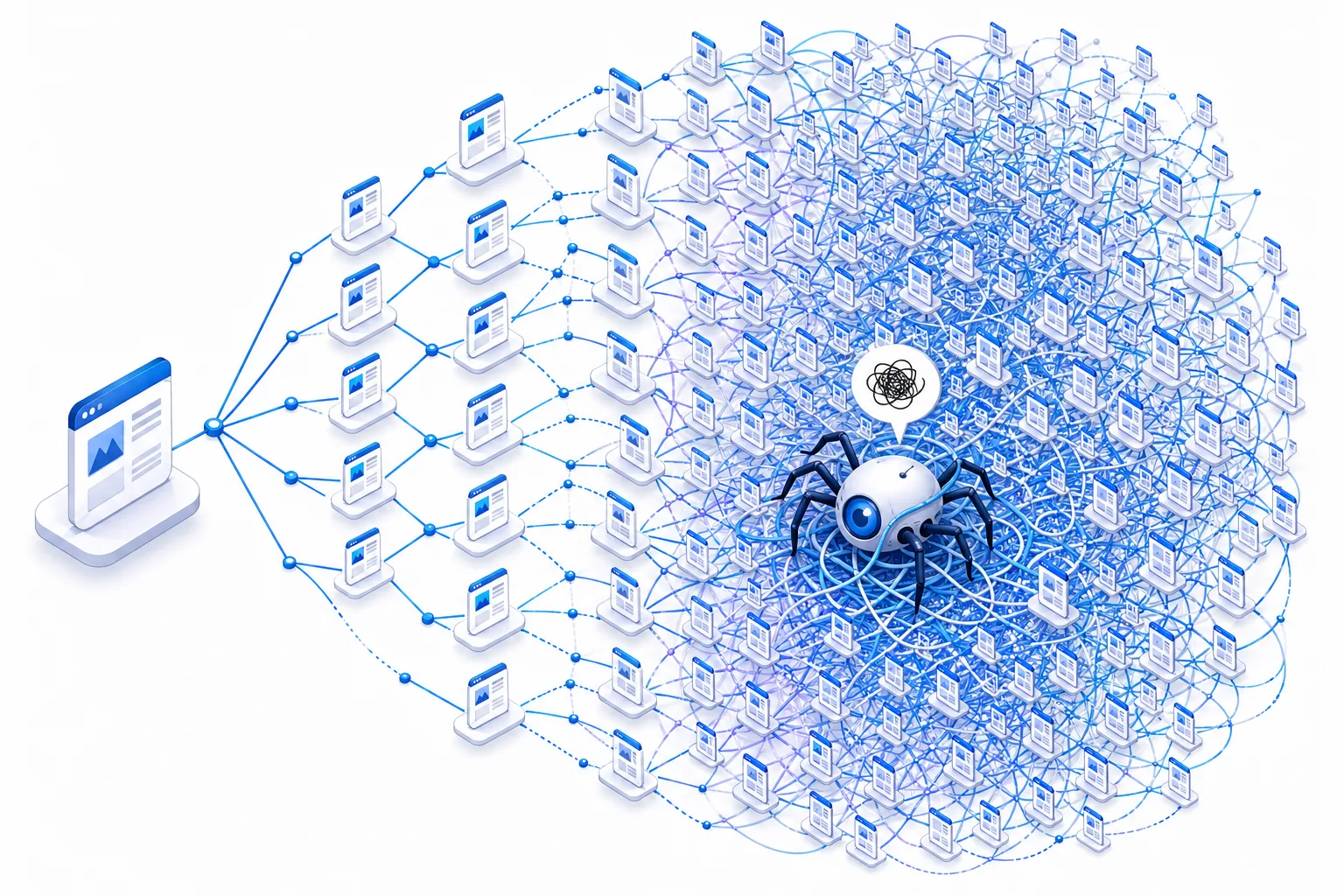
canonical、noindex、robots 与日志:分别管什么
参数治理不能把 canonical、noindex、robots 混成一个动作。它们解决的问题不同,必须按层次使用。
canonical:告诉搜索引擎首选 URL
canonical 的作用是合并重复信号,不是封锁抓取。它适合处理:
- 排序参数页归并到主列表页。
- 跟踪参数页归并到干净 URL。
- 某些筛选组合页归并到更强的规范页。
但要注意两点:
- canonical 是提示,不是强制。
- canonical 不能替代 URL 归一化,站内链接如果继续无限生成参数页,问题还会回来。
公开出处可参考:
- Google 关于规范重复 URL
noindex:允许抓取,但不进入索引
noindex 适合页面可以抓,但不值得收录的场景,比如低价值筛选页、内部搜索结果页、临时活动页。它的前提是页面必须能被抓取到,搜索引擎才能看到 noindex。
所以要记住:
- 不要把需要 noindex 的页面同时放进 robots.txt 里封掉。
- 如果被封了,搜索引擎看不到 noindex。
- 最终结果可能是既没抓到,也没及时退出索引。
公开出处可参考:
- Google 关于 robots meta 标记
robots.txt:只负责阻止纯噪音抓取
robots.txt 适合阻止那些你根本不想让搜索引擎访问的参数页,比如会话参数、纯跟踪参数、某些无限生成的技术路径。它的优势是省抓取,但缺点也很明显:它不负责理解页面内容,也不适合做精细索引控制。
公开出处可参考:
- Google 关于 robots.txt 阻止索引抓取
日志视角:用事实验证规则是否生效
规则写完不代表治理成功,必须回到日志验证:
- 参数 URL 的 bot 命中是否下降。
- 规范页是否拿回更多抓取。
- 低价值组合是否从高频抓取中退出。
- 301 是否把老参数 URL 稳定导向干净 URL。
- sitemap 中是否还残留参数页。
如果你在判断某个筛选组合到底该不该保留,建议先用 意图识别工具 判断搜索需求,再用 ROI 决策工作台 估算保留索引的收益。若页面模板大量由生成式流程拼出,还要用 AI 风险检查 看重复与低质风险。
可直接复制的代码与配置示例
示例 1:robots.txt 只拦截纯噪音参数
User-agent: *
Disallow: /*?*sessionid=
Disallow: /*?*jsessionid=
Disallow: /*?*sid=
Disallow: /*?*utm_source=
Disallow: /*?*utm_medium=
Disallow: /*?*utm_campaign=
Disallow: /*?*gclid=
Disallow: /*?*fbclid=
这段配置解决的是纯噪音 URL 被爬虫反复访问的问题。它适合会话参数和跟踪参数,因为这些参数页没有独立搜索价值,也不需要搜索引擎理解页面内容。
注意:
- 这段规则适合支持通配符的主流搜索引擎。
- 不要把需要 noindex 的页面也放进这里,否则搜索引擎看不到索引控制信号。
- 不要用 robots.txt 去拦截你还想保留抓取的分页页或重要筛选页。
示例 2:服务端 301 归一化 tracking / session 参数
const DROP = new Set([
'utm_source',
'utm_medium',
'utm_campaign',
'utm_term',
'utm_content',
'gclid',
'fbclid',
'sessionid',
'jsessionid',
'sid'
]);
app.use((req, res, next) => {
const origin = `${req.protocol}://${req.get('host')}`;
const current = new URL(req.originalUrl, origin);
const clean = new URL(req.originalUrl, origin);
for (const key of [...clean.searchParams.keys()]) {
if (DROP.has(key)) {
clean.searchParams.delete(key);
}
}
if (clean.pathname + clean.search !== current.pathname + current.search) {
return res.redirect(301, clean.pathname + clean.search);
}
next();
});
这段代码解决的是入口参数导致多个 URL 指向同一内容的问题。相比只靠 canonical,301 归一化更强,因为它会把旧参数 URL 直接收回到干净 URL,减少重复抓取,也减少用户分享、外链和内部跳转中的参数污染。
适合场景:
- 营销投放参数。
- 会话参数。
- 临时跟踪参数。
- 任何不应该长期留在地址栏里的技术参数。
示例 3:分页保留抓取,低价值筛选页 noindex
<?php
$base = 'https://www.example.com/category/shoes';
$page = isset($_GET['page']) ? max(1, (int) $_GET['page']) : 1;
$isThinFilter = isset($_GET['price']) || isset($_GET['color']) || isset($_GET['brand']);
$canonical = $base;
$robots = 'index,follow';
if ($page > 1) {
$canonical = $base . '?page=' . $page;
} elseif ($isThinFilter) {
$canonical = $base;
$robots = 'noindex,follow';
}
?>
<link rel='canonical' href='<?= htmlspecialchars($canonical, ENT_QUOTES) ?>'>
<meta name='robots' content='<?= $robots ?>'>
这段代码解决的是分页信号要保留,低价值筛选页要降噪的问题。它的核心逻辑是:
- page > 1 时,分页页自我规范化,保留抓取。
- 低价值筛选页不进入索引,但仍允许抓取,以便搜索引擎看到 noindex。
- 你可以把 isThinFilter 替换成自己的白名单判断,只让有搜索价值的组合进入索引。
电商、SaaS、B2B、本地服务分别怎么做
电商:分类页、排序页、筛选页要分开治理
电商最常见的问题是一个分类页衍生出几十种排序和筛选组合。建议做法是:
- 分类主页保留为规范页。
- page=2、page=3 等分页保留抓取,不要全量归并到第一页。
- sort=price、sort=new 这类仅改变排序的参数,默认 canonical 到分类主页。
- 颜色、尺码、品牌、价格区间等筛选组合,先做白名单。
- 有搜索需求的组合,尽量做成静态落地页,而不是依赖参数页。
例子:
- shoes?brand=nike&color=black 如果搜索需求稳定,可以做独立类目页。
- shoes?sort=price 通常不该独立收录。
- shoes?page=4 应保留抓取,帮助发现深层 SKU。
SaaS:帮助中心和对比页最容易被参数污染
SaaS 常见参数是 tab、sort、version、plan、compare。治理重点不是全部不收录,而是把真正有搜索价值的页面和纯交互状态区分开。
建议做法:
- pricing、compare、integrations 这类页面尽量用稳定静态 URL。
- ?tab=faq、?sort=popular 这类纯界面状态默认合并。
- 帮助中心分页保留抓取,避免文档被截断。
- 内部搜索结果页通常 noindex,follow。
例子:
- pricing?plan=enterprise 如果是营销落地页,做成独立页面更稳。
- docs?version=2.0 如果版本内容差异大,可单独保留。
- help?query=... 多数情况下不适合收录。
B2B:行业、地区、案例组合要谨慎
B2B 站点常见的是 industry=、region=、use_case= 这类筛选。问题在于很多组合只是销售过滤器,不是真正的搜索需求页。
建议做法:
- 把高价值行业页做成静态 URL,例如制造业、医疗、教育。
- 地区页只有在内容、案例、服务范围都足够时才保留。
- 案例列表分页保留抓取。
- 纯组合筛选页大多 noindex,follow。
例子:
- solutions?industry=manufacturing 如果你有专门案例和文案,可以保留。
- solutions?region=shanghai&industry=manufacturing 若只是交互筛选,不要放开索引。
- cases?page=2 应保留发现路径。
本地服务:不要让地图与半径筛选生成无限 URL
本地服务站点最容易出现位置参数爆炸,例如城市、区县、街道、半径、地图缩放、排序、营业时间等。治理重点是把可索引的服务区页面和地图交互状态分开。
建议做法:
- 城市或区域服务页做成静态 URL,例如 /shanghai/plumber/。
- 半径、距离、地图缩放等交互参数不进索引。
- 分店列表页和详情页保留抓取。
- 如果某个商圈页确实有本地搜索需求,再单独做静态落地页。
例子:
- service?city=shanghai&radius=5 通常不该收录。
- /shanghai/plumber/ 可以作为本地服务主落地页。
- stores?page=3 保留抓取,帮助发现更多门店。
常见错误:参数治理最容易踩的坑
错误 1:把 page=2、page=3 全部 canonical 到第一页
这会切断分页内容的发现路径。正确做法是分页页自我规范化,保留抓取,除非该分页页极薄且无独立价值。
错误 2:给需要 noindex 的页面加了 robots.txt 禁止抓取
这是最常见的误配之一。noindex 必须让页面被抓到,搜索引擎才能看到。先允许抓取,再通过 meta robots 控制索引。
错误 3:只改 canonical,不改站内链接和 sitemap
如果内部导航、筛选按钮、站内搜索结果页还在持续生成参数 URL,canonical 只能修结果,不能断源头。站内链接、模板和 sitemap 必须一起改。
错误 4:把所有筛选页都放开索引
参数一多,列表页会迅速变成同内容不同顺序的重复工厂。正确思路是白名单:只保留有明确需求、足够内容、可写独特标题和正文的组合页。
错误 5:忽略日志,只看收录数量
收录多不等于治理成功。你要看的是:
- 规范页抓取是否上升。
- 重复参数页是否下降。
- 重要列表页是否更快被更新。
- 参数页是否还在消耗大量 bot 请求。
落地顺序:先减量,再收口,再验证
如果你要在一个项目里真正做参数治理,建议按这个顺序执行:
1. 盘点全部参数,按排序、分页、会话、跟踪、筛选分类。
2. 从日志里找出抓取占比最高、价值最低的参数组合。
3. 对会话和跟踪参数先做 URL 归一化和 301。
4. 对分页建立 self canonical,不要乱合并到第一页。
5. 对筛选页做白名单,保留少量高价值组合,其余 noindex,follow。
6. 清理 sitemap、内链和模板输出。
7. 一到两周后回看日志和索引覆盖,确认抓取预算已经回流到规范页。
参数页治理的本质,不是少建 URL,而是让每一个 URL 都有明确角色。能承接搜索需求的,保留;只会制造重复的,收口;既要让搜索引擎抓得到,又不要让它收录的,用 canonical 和 noindex 分层处理。最后再用日志确认:预算有没有回到该去的地方。
下一课可以继续看: