SEO QA 流程怎么做:上线检查、回归验证与事故预防
SEO QA 流程怎么做:上线检查、回归验证与事故预防
SEO 事故大多数不是“算法突然变了”,而是改版、发布、模板调整、迁移和配置变更,把原本正确的索引信号改坏了。真正有效的 SEO QA,不是上线后看一眼首页,而是把检查拆成 上线前阻断、上线后回归、事故复盘和自动化预防 四层。
如果你负责的是电商、SaaS、B2B 或本地服务,这套流程都能直接落地;差别只在于检查对象和风险阈值不同。

为什么 SEO QA 必须工程化
SEO 事故的本质,是“信号被错误改写”
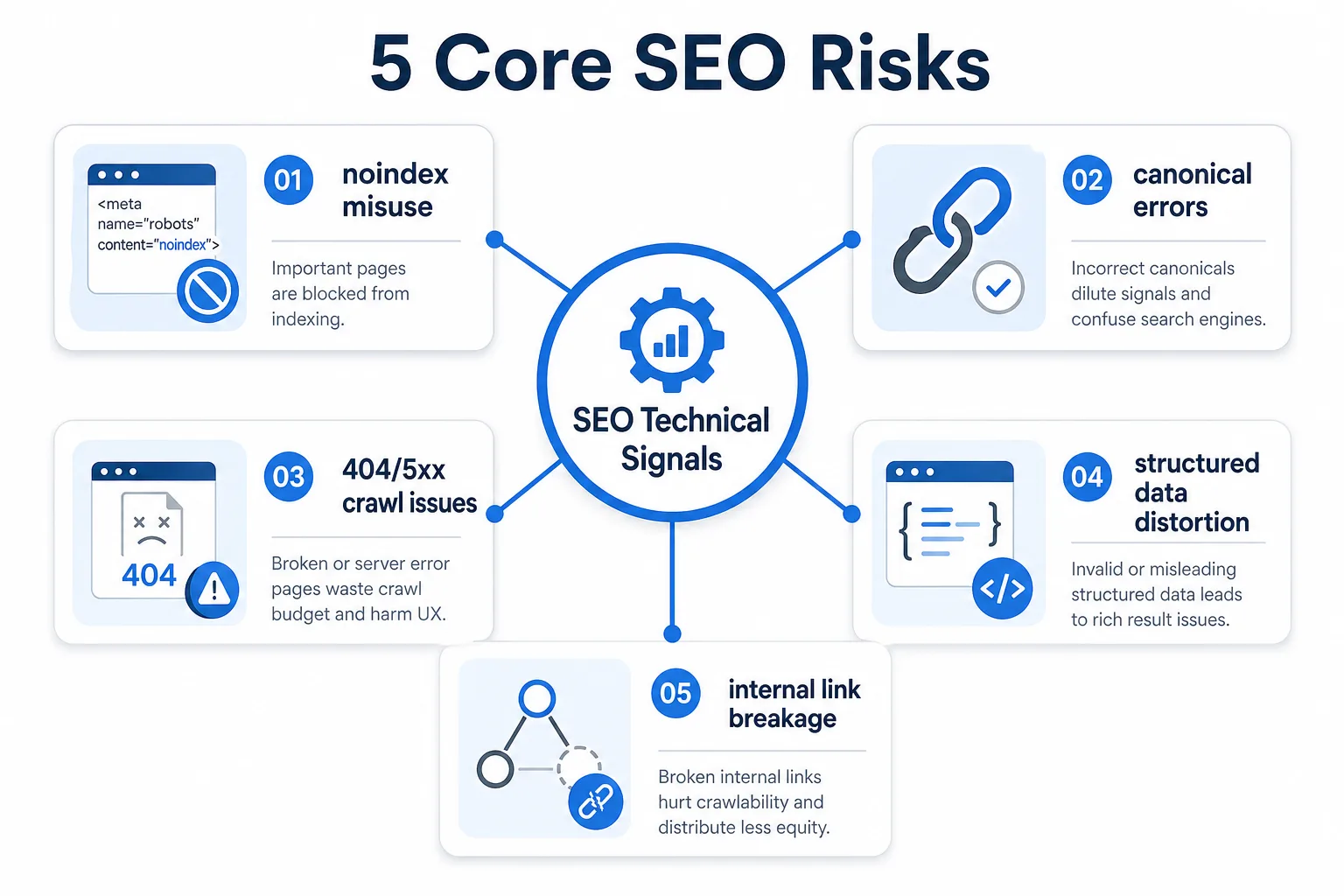
最常见的事故类型通常有五类:
- noindex 被误加:整站、目录页、活动页、详情页突然不可索引。
- canonical 指向错误:分页、筛选页、移动端或语言版本被统一到错误 URL。
- 404/5xx 扩散:旧链接失效、重定向链过长、模板拼接错误。
- 结构化数据失真:商品、FAQ、面包屑、组织信息缺字段或类型错误。
- 内链和信息架构变化:重要页面入口减少,抓取深度加深,权重传递中断。
Google Search Central 对 robots meta 标签、重复网址规范化 和 结构化数据 的说明很明确:这些不是“建议项”,而是会直接影响抓取、索引和结果展示的技术信号。
先定义你的 SEO QA 目标口径
QA 不是“查问题”,而是“验证发布是否保持了 SEO 资产”。建议把目标口径写成四个问题:
- 这次变更影响哪些 URL、模板、目录和参数规则?
- 哪些页面必须保持可索引、可规范化、可抓取?
- 哪些指标必须在发布后 24 小时内稳定?
- 一旦异常,谁负责回滚、修复和复验?
如果你需要判断某个改动是否会影响搜索意图、页面任务和转化路径,可以先用 Intent 工具 做页面意图校验;如果要评估标题、模板、规范化标签和文案改动的风险,可以配合 AI Risk 工具 先做变更风险扫描;如果要在修复优先级和业务收益之间做决策,再用 ROI Decision Workbench 排序。
上线前检查:把风险阻断在合并前
1. 做发布前清单,不要只看页面效果
上线前检查必须覆盖“代码、配置、内容、链接、索引信号”五类对象。建议每次发布都回答下面这些问题:
- 页面是否出现 noindex / nofollow 的误配置?
- canonical 是否仍然指向正确的最终 URL?
- 旧 URL 是否有可控的 301 映射,且没有重定向链?
- sitemap 是否包含了本次新增或替换的规范 URL?
- 重要内链是否被模板、面包屑、页脚或推荐模块误删?
- 结构化数据是否满足字段完整性和类型要求?
- robots.txt、X-Robots-Tag、meta robots 是否冲突?
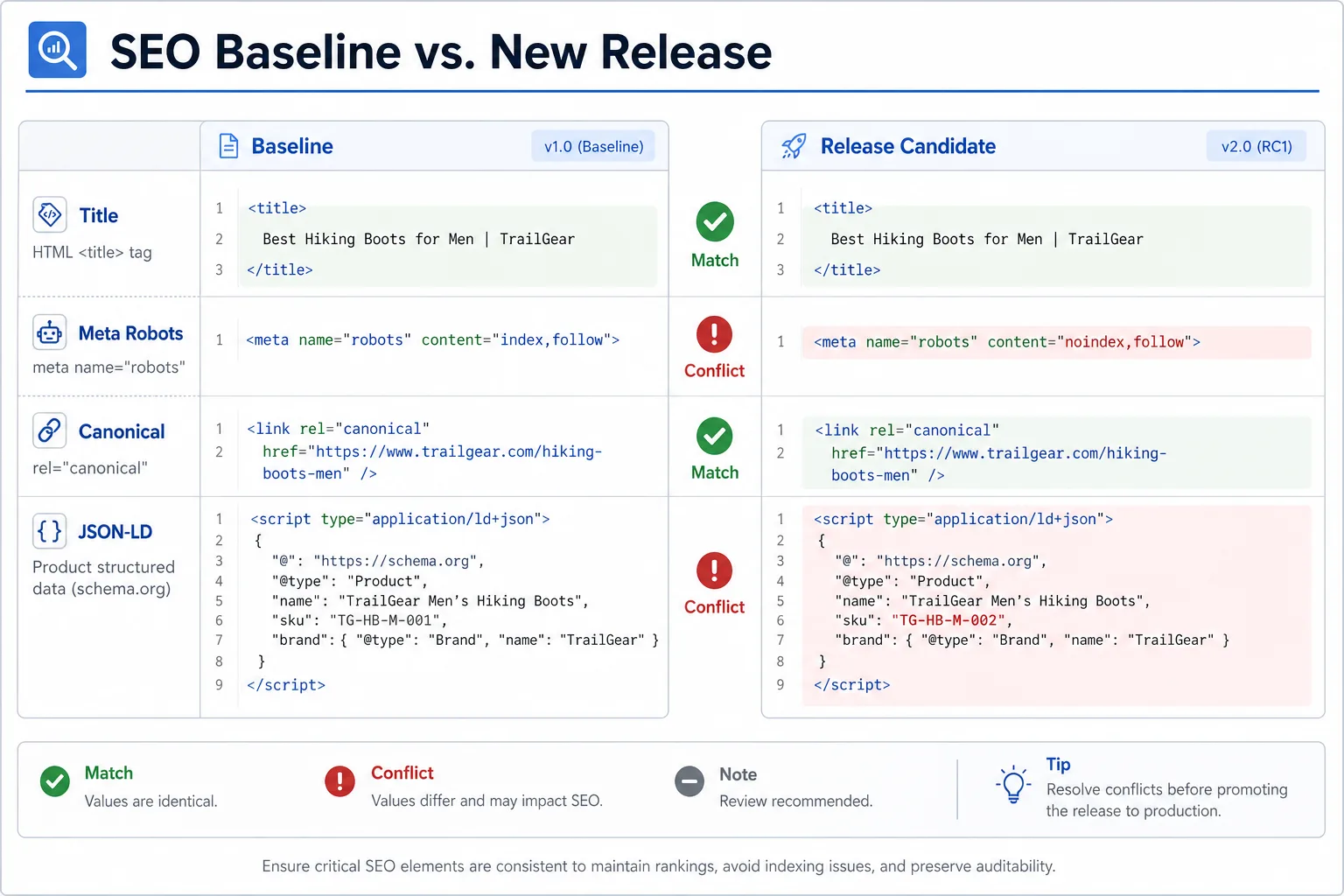
2. 上线前必须比对“发布前后差异”
不要只看新页面长什么样,要做 发布前后对比:
- URL 数量变化:新增、删除、重定向、404 的数量。
- 模板差异:head 区域、canonical、meta robots、hreflang、JSON-LD。
- 内链差异:关键页面入链数、首页入口、栏目入口、面包屑路径。
- 页面可见性差异:title、H1、首屏文案、产品/服务模块是否变化。
最实用的做法是建立一个 基线快照:发布前抓取 staging 和 production 的关键 URL,发布后再抓一遍做 diff。只要 head、状态码、canonical 或结构化数据出现变化,就进入人工复核。
3. 示例:正确的 head 配置长什么样
<head>
<meta charset="utf-8">
<title>示例页面标题</title>
<meta name="robots" content="index,follow">
<link rel="canonical" href="https://www.example.com/product/seo-tool">
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"name": "SEO Tool",
"brand": {
"@type": "Brand",
"name": "Example"
}
}
</script>
</head>
这段配置的作用很直接:
index,follow明确允许索引。- canonical 指向唯一规范地址,避免重复页分散权重。
- JSON-LD 提供结构化数据,便于搜索结果理解页面类型。
如果你在发布前发现模板里被误加了 noindex,应立即阻断合并,而不是等到上线后再补救。
回归验证:上线后 30 分钟、24 小时、72 小时分别看什么
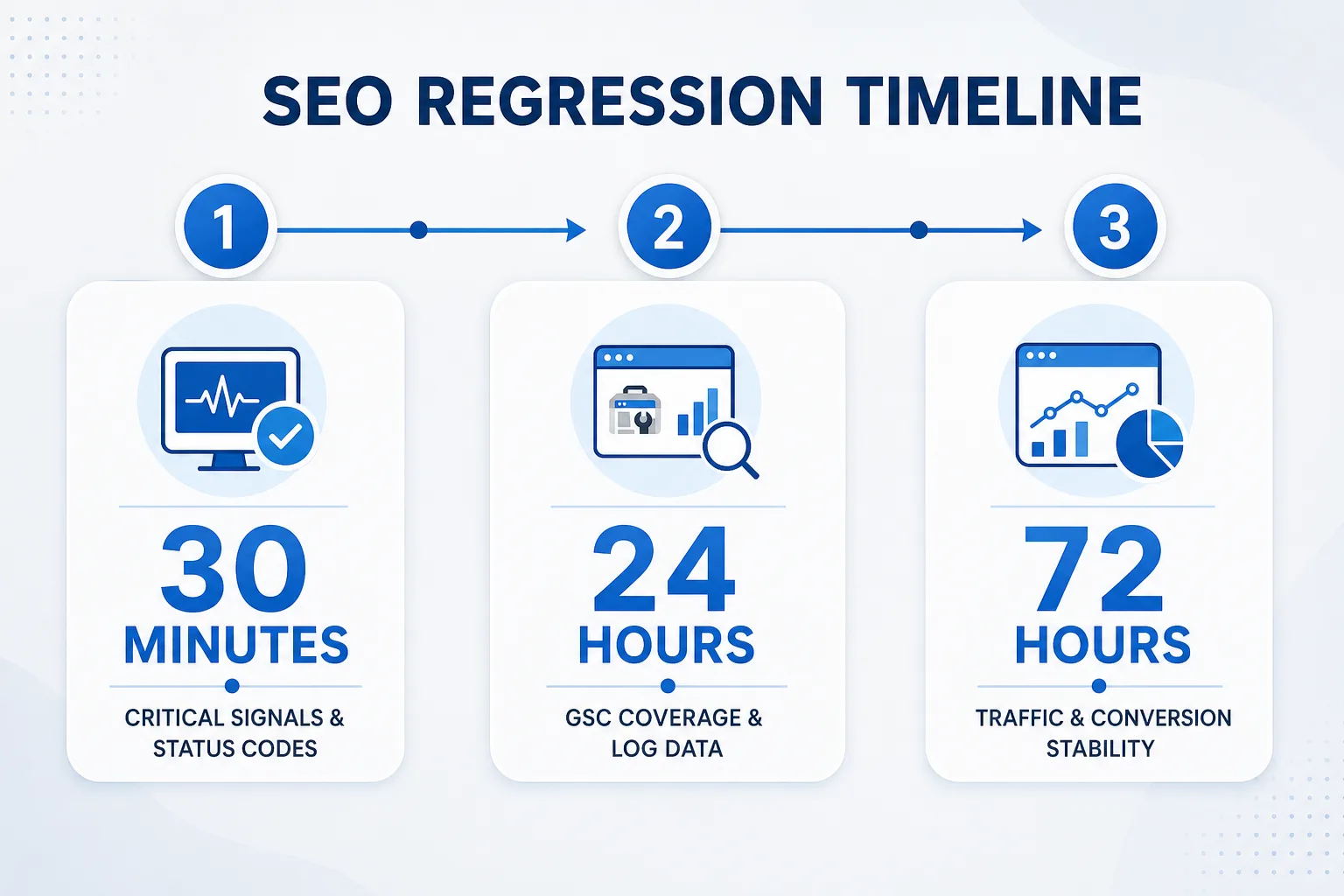
1. 30 分钟内:验证“没有基础性事故”
发布后第一轮验证,重点不是排名,而是以下硬指标:
- 核心 URL 返回 200,不是 3xx/4xx/5xx。
- canonical 与预期一致。
- meta robots 没有误加 noindex。
- 结构化数据可解析,没有语法错误。
- 关键导航、面包屑、页脚链接正常。
- sitemap 可访问且包含新规范 URL。
这一轮建议由开发或运维执行自动化脚本,SEO 负责审核结果。
2. 24 小时内:看抓取与索引信号是否偏移
24 小时后重点看:
- Search Console 是否出现覆盖率异常、重复页面、已发现但未编入索引、抓取错误。
- 日志里是否出现抓取深度突然加深、404 激增、重定向链增加。
- 新旧页面是否出现收录替换错误。
- 页面模板是否导致 title、description、canonical 批量变化。
3. 72 小时内:检查流量和页面群组是否恢复
72 小时后看业务层指标:
- 目标页面组的自然流量是否稳定。
- 核心关键词的落地页是否没有被错误替换。
- 转化页的点击率和表单/下单是否正常。
- 新旧页面是否出现异常分流。
4. 不同行业的回归重点
电商:重点检查商品、类目和筛选页
电商最怕的是:
- 商品页被误加 noindex。
- 类目分页 canonical 全部指向第一页。
- 筛选参数生成大量重复页但没有规范化策略。
- 缺货页、下架页的状态码和替代推荐处理不一致。
建议验证商品页、类目页、品牌页和活动页的模板差异,尤其是价格、库存、面包屑和相关商品模块。
SaaS:重点检查定价、功能页和文档页
SaaS 常见风险是:
- 定价页 canonical 错指到首页。
- 文档页被误设为 noindex。
- 英文/中文版本 hreflang 混乱。
- 新版文案替换后,搜索意图从“功能说明”变成“营销介绍”。
SaaS 团队应重点检查:功能页、对比页、帮助中心、API 文档、案例页和转化页。
B2B:重点检查案例、解决方案和落地页
B2B 网站常见问题是改版后信息架构变化过大:
- 案例页被合并,导致长尾词覆盖下降。
- 行业解决方案页的内链入口减少。
- 表单页被 SPA 改造后,首屏内容和可抓取文本不足。
建议把案例页、解决方案页、白皮书页和询盘页设为高优先级回归对象。
本地服务:重点检查门店、城市页和 NAP 信息
本地服务最怕的是:
- 城市页标题和地址模板批量出错。
- 门店页电话、地址、营业时间不一致。
- 地图、营业状态和预约入口失效。
- 多门店页面 canonical 全部指向总部页。
本地服务要重点核对 NAP 一致性、门店结构化数据和分站点页面的唯一性。
事故清单与 QA 工单:让问题可追踪、可复验
1. SEO 事故清单要按“可观测对象”分类
建议把事故清单拆成以下几类:
- 索引类:noindex、canonical、robots、sitemap、hreflang。
- 可用性类:404、500、重定向链、超时、JS 渲染失败。
- 内容类:标题、H1、正文缺失、重复、错位。
- 结构化数据类:类型错误、字段缺失、重复标记、富结果失效。
- 内链类:关键入口减少、面包屑断裂、导航丢失、分页不可达。
2. QA 工单必须写清“验收标准”
一个可执行的 SEO QA 工单,不应该只写“检查 SEO 问题”,而要写成明确验收项。下面是一个示例模板:
issue_type: seo_qa
release: 2025-03-product-template-v3
owner: seo-team
scope:
- /product/*
- /category/*
- /help/*
checks:
- name: meta_robots
expected: index,follow
- name: canonical
expected: self_canonical
- name: http_status
expected: 200
- name: schema
expected: valid_jsonld
- name: internal_links
expected: critical_links_present
acceptance:
- noindex_count == 0
- canonical_mismatch == 0
- 404_delta <= 5%
- structured_data_errors == 0
rollback_trigger:
- noindex_count > 0
- canonical_mismatch > 0
- 500_errors_spike == true
这份模板的作用是把“感觉有问题”变成“是否通过”。只要验收项是明确的,开发、测试、SEO、运维就能按同一口径执行。
3. 事故处理必须有回滚阈值
建议设置明确的回滚条件:
- 核心模板出现批量 noindex。
- canonical 误指向首页或非规范页。
- 重要页面 404 激增。
- 结构化数据大面积报错。
- 核心入链数下降超过预设阈值。
不要等排名明显掉了才回滚。SEO 事故的修复成本,通常远高于发布前的回滚成本。
自动化检查:让 SEO QA 进入 CI/CD
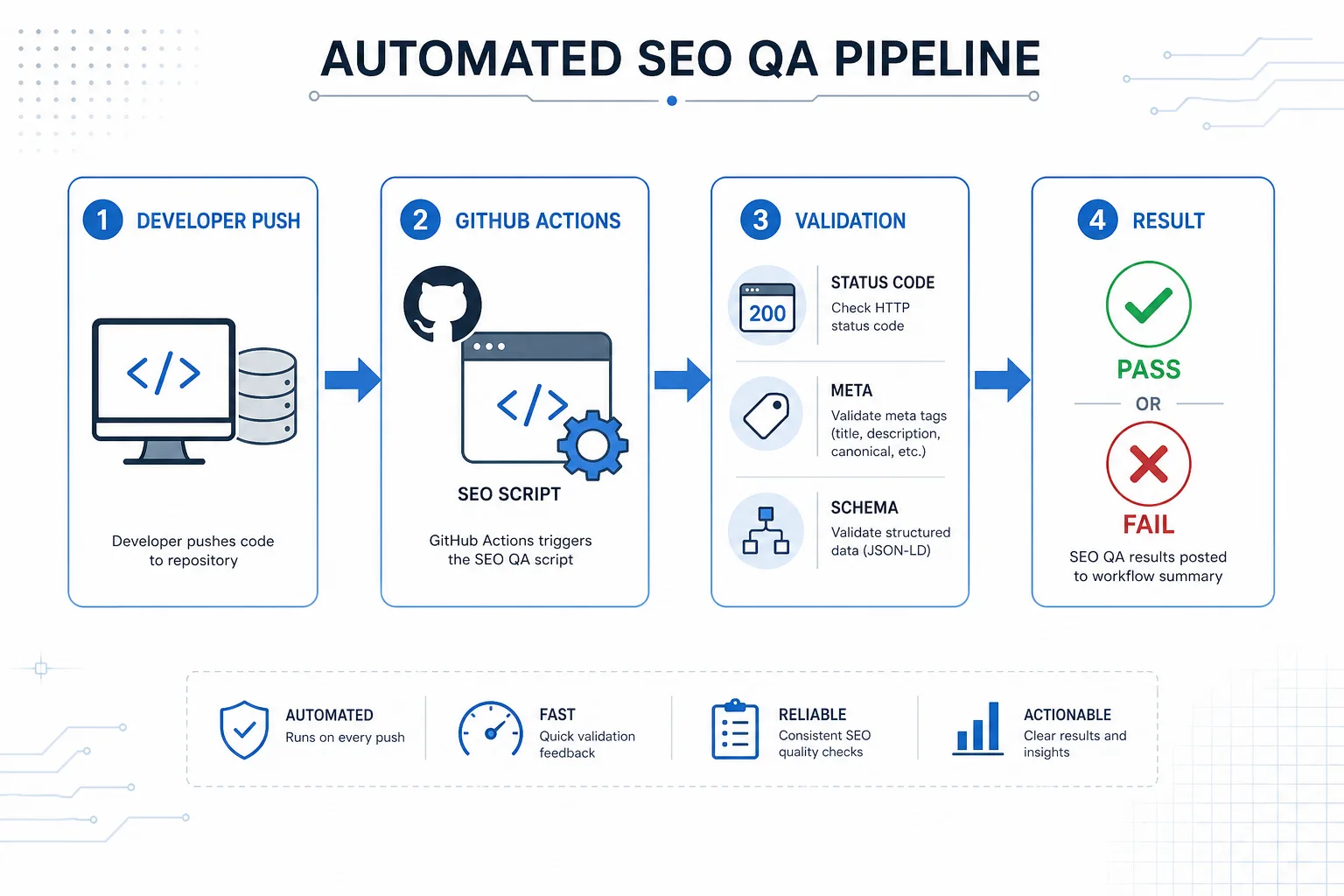
1. 用脚本做最小可行自动化
下面这个示例可以放进 CI 流程,在发布后快速检查页面是否误加 noindex、canonical 是否缺失、状态码是否异常:
#!/usr/bin/env bash
set -euo pipefail
URL="$1"
HTML="$(curl -sL "$URL")"
STATUS="$(curl -sI "$URL" | head -n 1 | awk '{print $2}')"
if [ "$STATUS" != "200" ]; then
echo "FAIL: status=$STATUS"
exit 1
fi
if echo "$HTML" | grep -qi 'noindex'; then
echo "FAIL: noindex found"
exit 1
fi
if ! echo "$HTML" | grep -qi '<link rel="canonical"'; then
echo "FAIL: canonical missing"
exit 1
fi
echo "PASS"
它的作用不是替代人工,而是把最容易出事故的基础项先拦住,减少低级错误上线。
2. 把检查接入 GitHub Actions 或发布流水线
name: seo-qa
on:
workflow_dispatch:
push:
branches:
- main
jobs:
validate:
runs-on: ubuntu-latest
steps:
- name: Check key URL
run: |
bash ./scripts/seo-qa-check.sh https://www.example.com/product/seo-tool
这个配置的作用是:只要主分支有发布,就自动验证关键 URL 的状态码与索引信号,避免“人忘了测”的问题。
3. 自动化最好同时看三类数据
- 页面层:status、canonical、meta robots、schema、title。
- 站点层:sitemap、robots、内链、重定向、404。
- 日志层:bot 抓取频次、异常路径、返回码分布。
如果团队规模足够,建议再加入 Search Console 数据、日志分析和页面抓取对比报表,形成发布后的自动告警。
事故预防:把一次 QA 变成长期机制
1. 设定责任人和审批链
SEO QA 不能只由 SEO 个人承担。建议最少明确以下角色:
- SEO 负责人:定义验收标准和风险优先级。
- 开发负责人:保证模板、路由、渲染逻辑正确。
- 测试负责人:执行回归和自动化验证。
- 运维/发布负责人:控制上线窗口、回滚和告警。
2. 用分层策略降低事故面
- 先灰度,再全量。
- 先改单页,再改模板。
- 先验证 staging,再验证 production。
- 先检查关键 URL,再检查全站。
3. 每次事故复盘都输出“预防项”
复盘不要只写原因,要强制输出三项:
- 这次事故是哪一个检查环节没覆盖到?
- 应该补哪条自动化规则?
- 下次发布前谁来确认?
例如:
- 如果是 canonical 错误,补“模板 canonical 单测”。
- 如果是 noindex 误加,补“发布前 head diff 检查”。
- 如果是 404 激增,补“旧 URL 301 映射验证”。
- 如果是结构化数据错误,补“JSON-LD 校验器”。
4. 最终目标不是“零问题”,而是“可快速发现、可快速回滚、可快速修复”
成熟的 SEO QA,不是保证永远不出问题,而是确保:
- 问题在上线前被发现。
- 上线后能在小时级识别。
- 事故能按预案回滚。
- 修复后能回归验证。
只要你的团队把 SEO QA 嵌入发布流程,noindex、canonical、404、结构化数据和内链事故就会从“线上灾难”变成“可控缺陷”。
下一课可以继续看: