SEO 数据仓库怎么搭:搜索数据、内容数据与转化数据打通
SEO 数据仓库怎么搭:搜索数据、内容数据与转化数据打通
SEO 数据仓库的目标,不是把 GSC、GA4、CMS、CRM 拼成一张巨宽表,而是把“搜索表现、内容资产、业务结果”放到同一套口径里,能追溯、能归因、能自动校验。
如果你只想先跑最小闭环,优先接入 GSC + GA4 + CMS + CRM;如果你要把内容优先级和商业价值连起来,可以先用 SEO Intent 分析工具 给 query 和页面打意图标签,再用 AI 风险检测 排查重复、低质和机器痕迹,最后用 ROI 决策工作台 给选题、改版和迭代排序。

一、先定口径:数据仓库不是报表拼接
1.1 你要先回答的 5 个问题
- 哪些搜索词真正带来了高质量流量,而不是只带来点击?
- 哪些 URL 被多个 query 反复触达,存在内容蚕食或意图混乱?
- 哪些内容模板在不同意图、不同设备、不同地区下最稳定?
- 哪些页面只贡献曝光,不贡献会话、线索、订单或预约?
- 哪些 SEO 改动,最终影响了收入、试用、MQL、SQL 或到店?
如果仓库回答不了这些问题,就不要急着做大屏,而要先补数据结构和口径。
1.2 推荐的数据链路
建议采用标准分层:Raw -> Staging -> Dim/Fact -> Mart -> Dashboard。
- Raw:原始抽取,保留源系统字段,不做业务解释。
- Staging:清洗、去重、标准化时间、币种、时区、URL。
- Dim/Fact:维表和事实表,保证主键和粒度稳定。
- Mart:面向业务的汇总层,例如按页面、主题集群、渠道、国家、设备汇总。
- Dashboard:只读展示层,不允许在这里做临时口径。
公开字段规则先看官方文档:Google Search Console 性能报表说明见 https://support.google.com/webmasters/answer/7576553?hl=zh-Hans ,GA4 导出到 BigQuery 的说明见 https://support.google.com/analytics/answer/9358801?hl=zh-Hans 。如果你要处理重复 URL 和规范化地址,Google 的说明见 https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls?hl=zh-cn 。
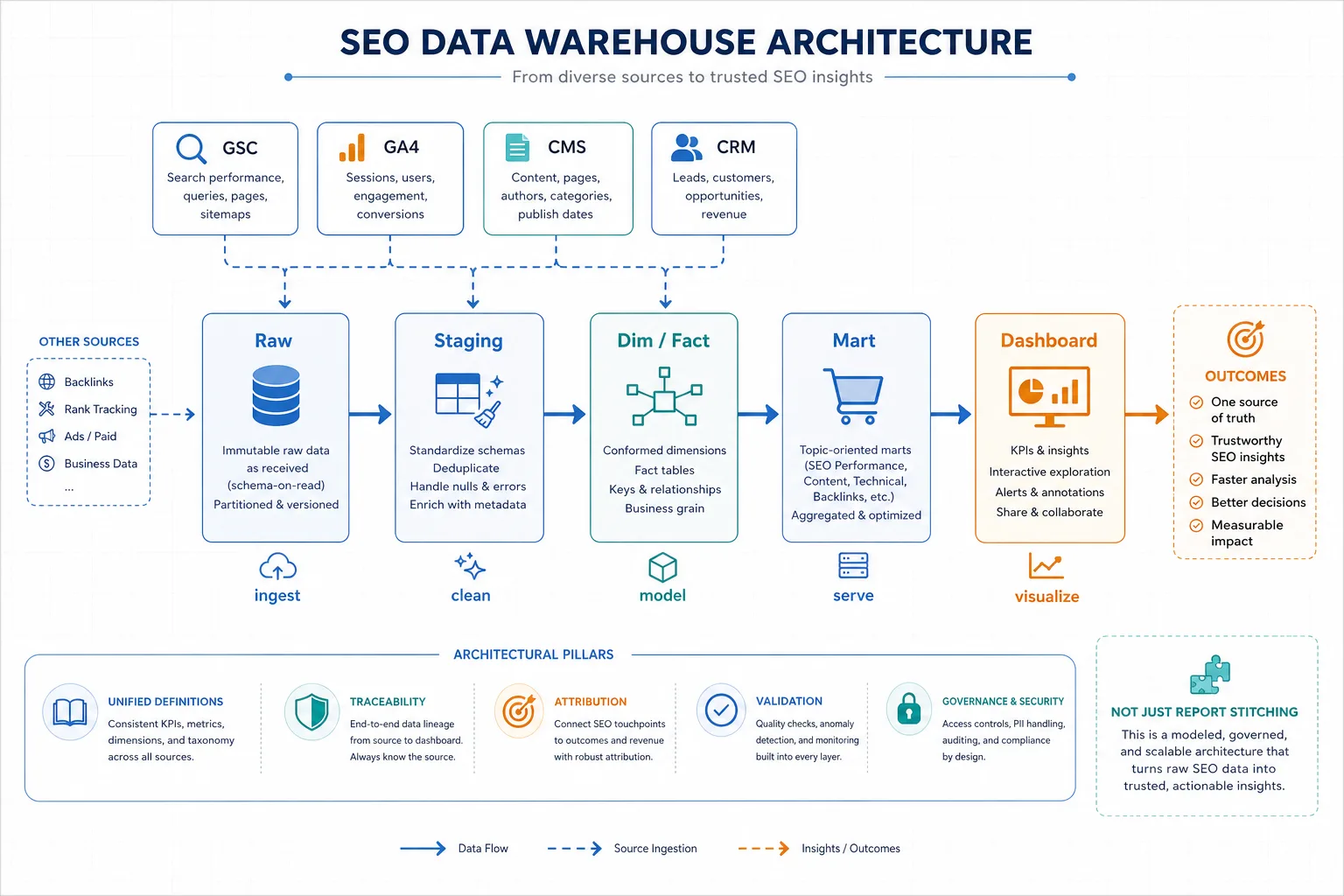
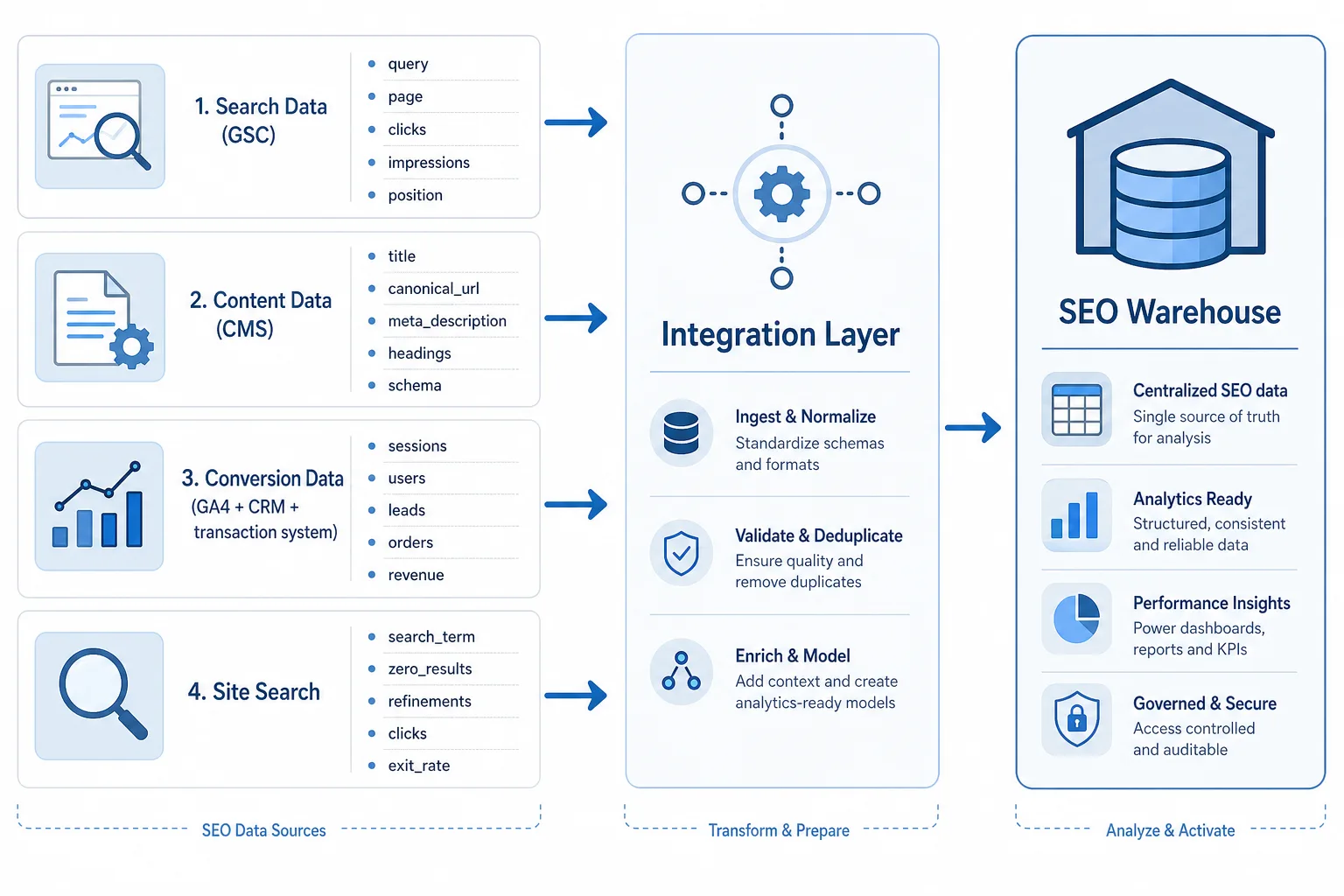
二、数据源怎么接
2.1 搜索数据:GSC 是“搜索侧事实”,不是业务结果
GSC 至少要抽取这些字段:
- date
- query
- page
- device
- country
- clicks
- impressions
- ctr
- position
关键约束:
- GSC 只代表 Google 搜索侧数据,不代表站内搜索,也不代表 GA4 会话。
- query 和 page 的关系是搜索侧关系,不要直接等同于会话落地页。
- 如果站点有多语言、多地区,必须保留 locale、country、device 三个维度。
2.2 内容数据:CMS 决定“这是什么页面”
CMS 侧至少要保留这些字段:
- cms_content_id
- raw_url
- title
- h1
- template
- author / owner
- publish_time
- update_time
- status
- category / topic_cluster
- content_type
- locale
- canonical_url
内容数据的价值不只是“标题是什么”,而是告诉仓库:这个 URL 属于哪个内容资产、哪个模板、哪个主题集群、哪个业务阶段。
2.3 转化数据:GA4 + CRM + 交易系统要分层存
转化数据通常来自三类系统:
- GA4:session、engaged session、事件、站内路径、登陆页来源。
- CRM:lead、contact、account、opportunity、stage、pipeline_value。
- 交易或预约系统:订单、订阅、试用、电话、表单、预约、到店。
不同业务模型要对应不同结果指标:
- 电商:订单、收入、毛利、AOV、复购。
- SaaS:试用、激活、升级、MRR、留存、流失。
- B2B:MQL、SQL、机会、pipeline、win rate。
- 本地服务:电话、预约、到店、路线点击、分店转化。
2.4 站内搜索:最容易被忽略的需求信号
站内搜索不要只存关键词,还要存:
- search_query
- normalized_query
- results_count
- zero_result_flag
- refinement_count
- click_after_search
- downstream_conversion
站内搜索能告诉你:用户在站内没找到什么、需要什么、下一步想做什么。零结果率高的词,往往就是内容缺口或导航缺口。
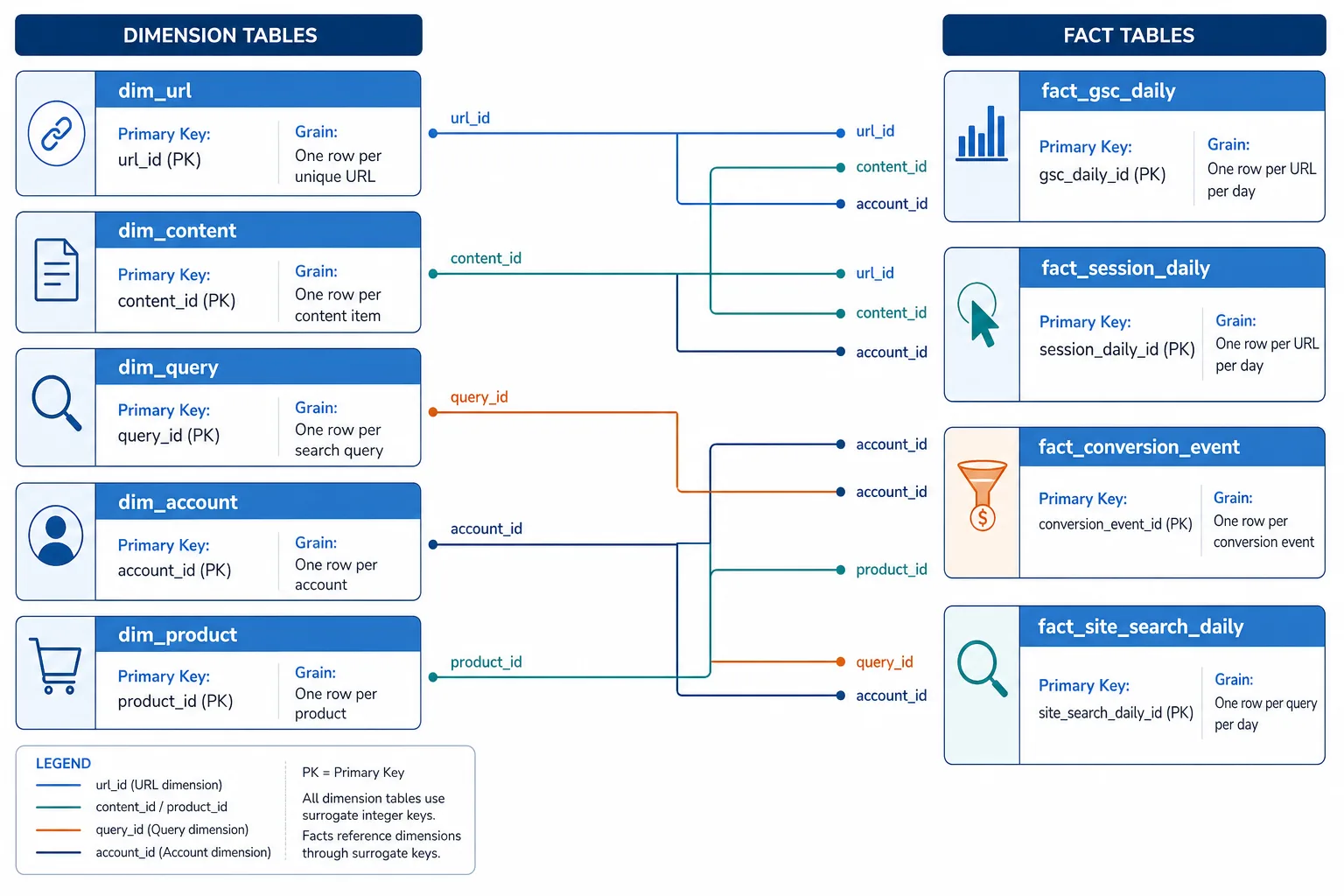
三、核心表结构:先建维表,再建事实表
3.1 推荐的维表
| 表名 | 粒度 | 主键 | 关键字段 |
|---|---|---|---|
| dim_url | 一条标准化 URL | url_id | raw_url, normalized_url, canonical_url, redirect_target, host, path, query_signature, locale, content_type, indexability |
| dim_content | 一条内容资产 | content_id | cms_content_id, url_id, title, h1, template, topic_cluster, intent_tag, funnel_stage, owner, publish_time, update_time |
| dim_query | 一个归一化搜索词 | query_id | normalized_query, brand_flag, intent_tag, entity_tag |
| dim_account | 一个客户或账户 | account_id | crm_account_id, segment, industry, region, sales_owner |
| dim_product | 一个商品、套餐或服务 | product_id | sku, service_line, plan_name, price_band, margin_band |
3.2 推荐的事实表
| 表名 | 粒度 | 主键建议 | 核心指标 |
|---|---|---|---|
| fact_gsc_daily | date + url + query + device + country | date, url_id, query_id, device, country | clicks, impressions, ctr, avg_position |
| fact_session_daily | session 或 date + landing_url + source + device | session_id 或组合键 | sessions, engaged_sessions, conversions, revenue |
| fact_conversion_event | 一个业务事件 | event_id | lead, order, trial, booked_call, value, stage |
| fact_site_search_daily | date + query + device | date, query_id, device | searches, zero_results, refinements, conversions |
3.3 主键和粒度怎么定
这是仓库成败的关键。
- 维表用稳定的 surrogate key,例如 url_id、content_id、query_id。
- 事实表必须先写清楚“这一行代表什么”。
- 不要直接把 raw_url 当主键,因为参数、尾斜杠、重定向、canonical 都会变。
- 不要把 session 明细和 query 明细直接拼到一张大表,先在各自粒度聚合,再做受控 join。
所有表都建议带上这些通用字段:
- source_system
- ingested_at
- etl_run_id
- business_date
- updated_at
四、URL 归一:仓库成败的分水岭
4.1 归一规则
URL 归一必须先定义规则,再写代码。
- 去掉 hash fragment。
- 去掉跟踪参数,例如 utm、gclid、fbclid、msclkid。
- 统一尾斜杠规则。
- host 全小写。
- 路径大小写是否统一,要按站点规则决定,不要盲目强制。
- 解析 redirect,保留最终可索引 URL。
- 解析 canonical,建立 canonical_url 到 raw_url 的映射。
- 多语言站点要保留 locale,不要把不同语言页误合并。
4.2 一定要单独建 URL 映射表
建议加一张 bridge_url_alias 或 dim_url_alias,记录:
- raw_url_id
- canonical_url_id
- redirect_target_url_id
- reason
- valid_from
- valid_to
这样做有两个好处:
- 改版后不会丢历史。
- 你可以回溯某个旧 URL 的搜索表现和转化结果。
4.3 URL 归一函数示例
def normalize_url(raw_url):
u = urlsplit(raw_url)
host = u.netloc.lower()
path = u.path.rstrip('/')
keep = []
for k, v in parse_qsl(u.query):
if not k.startswith('utm_') and k not in ['gclid', 'fbclid', 'msclkid', 'yclid']:
keep.append((k, v))
query = urlencode(sorted(keep))
return urlunsplit((u.scheme.lower(), host, path, query, ''))
作用:
- 去掉营销参数,避免一个页面被拆成多份。
- 将同一页面的搜索、内容、转化统一到同一个 url_id。
- 为后续 GSC、GA4、CMS、CRM join 提供稳定键。

五、指标口径与归因
5.1 搜索表现口径
| 指标 | 定义 | 来源 | 说明 |
|---|---|---|---|
| clicks | 搜索结果点击次数 | GSC | 只代表搜索侧点击,不等于会话 |
| impressions | 搜索结果曝光次数 | GSC | 用于判断覆盖和可见度 |
| ctr | clicks / impressions | GSC | 适合做标题、摘要和意图匹配分析 |
| avg_position | 平均排名 | GSC | 适合做排名带宽和波动监控 |
注意:GSC 的 clicks 不能直接等于 GA4 的 sessions。一个点击可能因为页面跳转、拦截、离开很快、隐私限制等原因,不一定形成完整会话。
5.2 内容与转化口径
| 指标 | 定义 | 来源 | 备注 |
|---|---|---|---|
| organic_sessions | source/medium 归因到 organic 的会话 | GA4 | 建议保留 landing page 维度 |
| engaged_session_rate | engaged_sessions / sessions | GA4 | GA4 默认口径要写入字典 |
| conversion_rate | conversions / organic_sessions | GA4 / CRM / 交易系统 | 口径要按业务类型拆分 |
| revenue_per_organic_session | organic revenue / organic_sessions | 交易系统 + GA4 | 电商和订阅业务尤其重要 |
| lead_rate | leads / organic_sessions | CRM | B2B 常用 |
| booking_rate | booked_calls / organic_sessions | 预约系统 | 本地服务常用 |
5.3 归因要分三层
SEO 数据仓库至少要同时支持三层归因:
- 搜索侧归因:GSC 的 query -> page 关系。
- 会话侧归因:GA4 的 session source / medium、landing page、device、country。
- 业务侧归因:CRM、订单、试用、预约、到店等结果。
建议默认做法:
- 报表层使用 last non-direct 作为基础归因。
- 决策层同时保留 first touch、last touch、assist touch。
- B2B 以 account 为主,不要只看单个 lead。
- 长销售周期建议设置 30 天、60 天、90 天多窗口归因。
本地服务要特别注意:电话、表单、路线点击、门店预约通常不在同一系统里,要通过 location_id 或 branch_id 统一。
六、代码与配置示例
6.1 dbt 风格的数据质量测试
下面这段配置的作用,是把主键唯一性、非空、跨表关联放进自动化测试,避免重复行和脏 join 进入报表。
version: 2
models:
- name: dim_url
columns:
- name: normalized_url
tests:
- not_null
- unique
- name: fact_gsc_daily
tests:
- dbt_utils.unique_combination_of_columns:
combination_of_columns:
- business_date
- url_id
- query_id
- device
- country
columns:
- name: url_id
tests:
- not_null
- relationships:
to: ref('dim_url')
field: url_id
解释:
normalized_url唯一,保证一个标准 URL 只对应一个内容资产。unique_combination_of_columns防止同一粒度重复灌数。relationships保证事实表能回连维表,避免孤儿数据。
6.2 事实层聚合后再 join 的示例
这段 SQL 只演示方法:先把各源按统一粒度聚合,再做 join,避免明细表互相笛卡尔放大。
with gsc as (
select
business_date,
url_id,
sum(clicks) as clicks,
sum(impressions) as impressions
from fact_gsc_daily
group by 1, 2
),
ga4 as (
select
business_date,
landing_url_id as url_id,
countif(is_engaged_session) as engaged_sessions,
countif(is_conversion) as conversions,
sum(revenue) as revenue
from fact_session_daily
group by 1, 2
)
select
gsc.business_date,
gsc.url_id,
gsc.clicks,
gsc.impressions,
ga4.engaged_sessions,
ga4.conversions,
ga4.revenue
from gsc
left join ga4
on gsc.business_date = ga4.business_date
and gsc.url_id = ga4.url_id;
解释:
- GSC 和 GA4 先各自收敛到同一粒度。
- url_id 作为统一键,把搜索表现和业务结果接起来。
- 最终 mart 层才适合给 dashboard 使用。
6.3 建议的 URL 归一逻辑清单
如果你要把它落到 ETL 里,建议配置成可版本化规则,而不是写死在代码中:
- 保留 canonical 版本。
- 保留 redirect 链路。
- 过滤营销参数。
- 保留业务参数白名单,例如分页、筛选、语言切换。
- 记录规则版本号,方便回滚。
七、仪表盘怎么做才可用
7.1 管理层看什么
管理层不需要看全量 query 明细,优先看这些聚合指标:
- 总点击、总曝光、总 CTR、平均排名
- organic sessions、engaged session rate
- 订单、线索、试用、预约、收入、pipeline
- 内容覆盖率、页面健康度、零结果率
- 数据 freshness 和失败率
建议把这几个图放在首页:
| 看板 | 目的 | 核心指标 | 刷新频率 |
|---|---|---|---|
| SEO 总览 | 看趋势和风险 | clicks, impressions, ctr, avg_position | 日更 |
| 内容总览 | 看资产效率 | content traffic, engaged rate, conversions | 日更 |
| 转化总览 | 看业务结果 | revenue, leads, trials, bookings | 日更或小时级 |
| 数据健康 | 看仓库是否可信 | freshness, null rate, join rate, duplicate rate | 小时级或日更 |
7.2 SEO、内容、增长、工程各看什么
- SEO 团队:query-page 匹配、关键词蚕食、页面衰减、索引覆盖、模板差异。
- 内容团队:主题集群表现、标题/摘要 CTR、不同意图的内容转化、老内容更新收益。
- 增长团队:渠道协同、 landing page 转化、归因窗口、收入贡献。
- 工程团队:采集失败、字段缺失、URL 映射异常、 canonical 冲突、404 激增。
如果你要先做一个能落地的优先级面板,可以把问题页、收益页和低风险高收益页分别放进 ROI 决策工作台。
八、四个行业怎么落地
8.1 电商:URL 要映射到 SKU、类目和库存
电商仓库最重要的是把内容页和交易页接起来。
建议增加这些维度:
- product_id / sku
- category_id
- brand_id
- inventory_status
- price_band
- margin_band
重点指标:
- 类目页点击率和转化率
- 产品页到加购率、购买率
- 缺货页的自然搜索损失
- 富结果页面的曝光和点击
归因时不要只看订单归因,还要看助攻价值:某些类目页不直接成交,但会显著抬升后续购买。
8.2 SaaS:从内容到试用,再到激活和升级
SaaS 的核心不是点击,而是试用、激活和升级。
建议在仓库里保留:
- trial_started
- activation_completed
- feature_used
- upgrade_started
- upgrade_completed
- churned
内容层重点看:
- 解决方案页
- 功能页
- 对比页
- 用例页
- 定价页
SaaS 常见错误是只看表单提交,不看后续激活和付费。真正有价值的 SEO 页面,应该能拉动 trial 到 activation 的转化链路。
8.3 B2B:以 account 为中心,不要只盯 lead
B2B 销售周期长,单个 lead 价值不稳定,仓库最好以 account 为主线。
建议保留:
- account_id
- contact_id
- lead_id
- opportunity_id
- stage
- pipeline_value
- sales_owner
- industry
- company_size
重点指标:
- organic 带来的 MQL、SQL、机会数
- 机会金额和赢单率
- 平均销售周期
- 内容触点数量和阶段推进率
B2B 的 SEO 仓库应支持“第一页触达、最后一次触达、助攻触达”三种视角,否则你很难解释内容对 pipeline 的真实贡献。
8.4 本地服务:把页面、门店和预约系统统一起来
本地服务特别容易被漏算,因为转化入口很多:电话、表单、路线点击、在线预约、到店。
建议保留:
- branch_id / location_id
- service_area
- call_tracking_id
- booking_id
- route_click
- form_submit
重点指标:
- 本地页的自然搜索曝光和点击
- 路线点击率
- 电话转化率
- 预约完成率
- 分店之间的搜索覆盖差异
本地业务里,地名词和服务词往往一起出现。页面必须把地理实体和服务实体统一建模,否则你会把真实需求拆散。
九、自动化验证与事故预防
9.1 每天至少跑这些校验
- 原始抽取行数是否和源系统大致一致。
- url_id、content_id、query_id 是否有空值。
- GSC 到 dim_url 的映射率是否下降。
- GA4 landing page 到 dim_url 的 join rate 是否异常。
- CRM 的 account_id、lead_id、opportunity_id 是否断链。
- 同一粒度是否出现重复主键。
- 数据延迟是否超过 SLO。
建议设一个 quarantine 表:凡是无法归一、无法映射、字段缺失严重的数据先进入隔离区,不要直接进正式 mart。
9.2 最常见的事故场景
- CMS 改版导致 URL 结构变化,但历史事实表没有做 alias 映射。
- 参数规则变更,utm 或筛选参数被误当成新页面。
- GSC、GA4、CRM 的时区不一致,日级报表对不上。
- 一个页面同时有 canonical、redirect、noindex 冲突,导致数据和索引状态不一致。
- 报表直接用明细 join,结果数字被放大。
9.3 事故预防清单
- 所有 URL 规则必须版本化。
- 所有事实表必须写明粒度。
- 所有 KPI 必须写入数据字典。
- 所有 dashboard 必须显示最近更新时间。
- 所有异常波动先检查数据 freshness,再检查业务变化。
- 改版前先冻结映射表,改版后再补充 alias。
十、落地顺序建议
如果团队刚开始搭 SEO 数据仓库,建议按这个顺序推进:
- 先把 GSC、GA4、CMS 接起来。
- 再补 URL 归一和内容映射。
- 接入 CRM、订单或预约系统。
- 建立核心维表和事实表。
- 加上数据质量测试和告警。
- 最后再做大屏和高阶归因。
真正可用的 SEO 数据仓库,不是“字段越多越好”,而是“主键稳定、口径一致、自动校验、事故可回溯”。只要这四件事做到位,搜索数据、内容数据和转化数据就能真正连起来。
下一课可以继续看: