SEO 分页怎么做:列表页、无限滚动、分页信号与索引策略
SEO 分页怎么做:列表页、无限滚动、分页信号与索引策略
分页的 SEO 重点不是把内容拆开,而是把每一层列表都变成可抓取、可理解、可维护的索引路径。做对了,深层内容能被发现;做错了,常见后果是重复页、薄页、参数污染和抓取预算浪费。
如果你正在判断某个列表页到底该不该开放索引,先用 意图判断工具 识别页面意图,再用 ROI 决策工作台 估算投入产出;如果模板可能批量生成相似文案,先用 AI 风险检测工具 过滤重复和薄页风险。

先定规则:分页是页面职责,不只是界面组件
先记住一句话:分页的核心不是分页器,而是 URL 和索引信号的设计。只要页面被搜索引擎抓取,分页就不再只是前端交互,而是内容发现系统的一部分。
Google 的官方原则可以先看这三篇:
- 重复网址规范化
- robots meta 标签
- JavaScript SEO
一张表先看清楚
| 页面类型 | 默认策略 | 索引建议 | 备注 |
|---|---|---|---|
| 商品列表页 | 普通分页或加载更多 | 通常可索引 | 每页要有独立价值 |
| 文章列表页 | 普通分页 | 可索引 | 深层文章要能被发现 |
| 案例列表页 | 普通分页或加载更多 | 可索引 | 尤其适合 B2B 和 SaaS |
| 站内搜索结果页 | 分页但默认谨慎 | 通常 noindex,follow | 查询空间过大、重复多 |
| 筛选和排序页 | 参数分页 | 只保留少量可索引组合 | 其余做规范化或 noindex |
| 空结果页 | 不建议保留为索引页 | 视情况 404、410 或 noindex | 防止薄页堆积 |
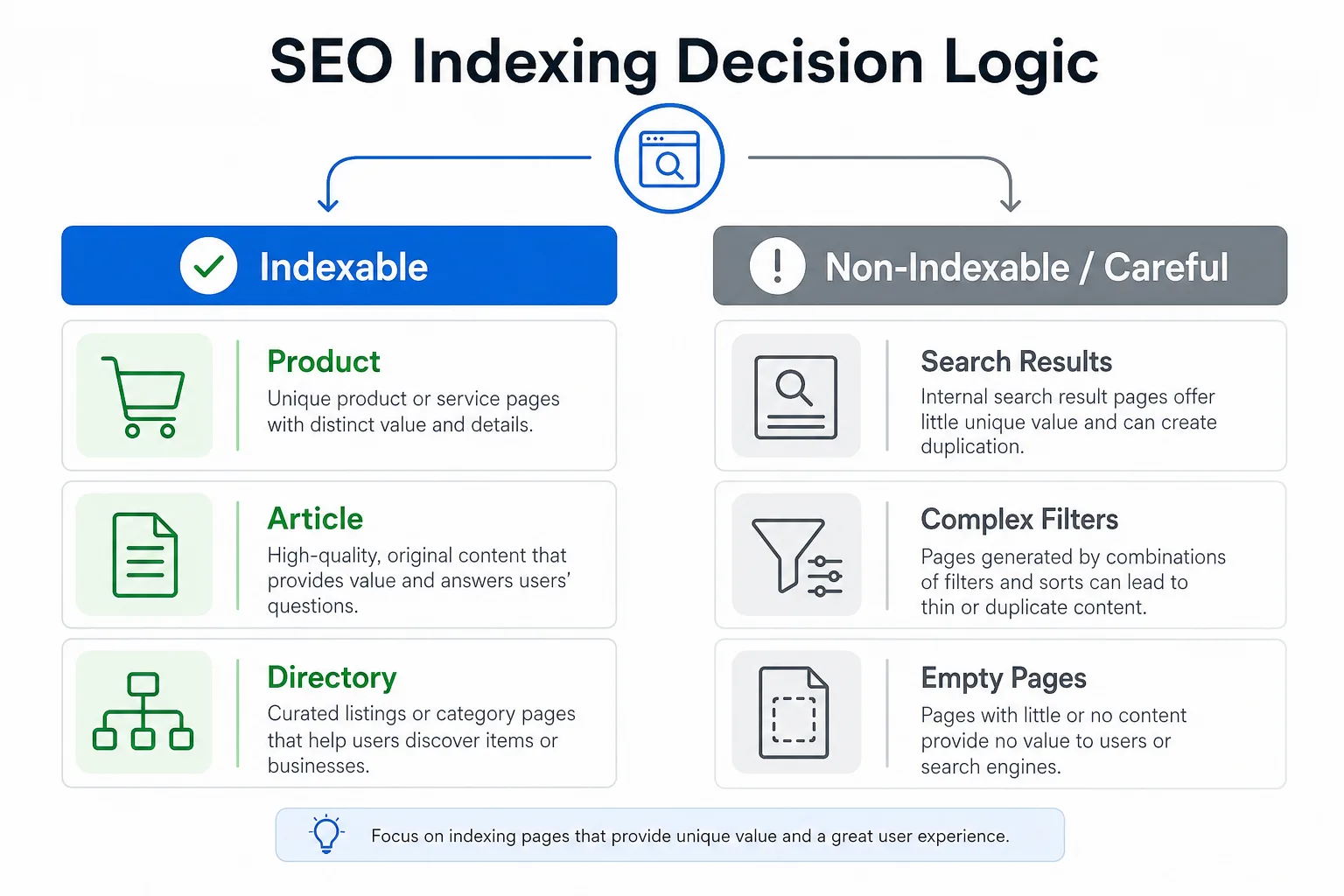
一、先判断哪些列表页应该索引
电商、文章、案例、目录页:默认可索引
这类页面的共同点是:列表本身有导航价值,分页后的每一页都能承载不同的实体内容。
适合开放索引的典型场景:
- 商品列表:每页展示不同 SKU
- 文章列表:每页展示不同内容条目
- 案例列表:每页展示不同项目
- 目录页:每页展示不同服务、门店、资源
搜索结果页、筛选页、排序页:默认谨慎
这些页面容易因为参数组合爆炸而产生大量重复 URL。通常做法是:
- 站内搜索结果页:默认 noindex,follow
- 非核心筛选组合:默认不索引
- 只有少量业务上重要的筛选组合,才做成独立落地页
用意图判断决定索引边界
如果一个列表页的目标是“帮助用户继续发现内容”,它就有索引价值;如果它只是“临时展示一组筛选结果”,它大概率不值得开放索引。资源有限时,先用 意图判断工具 把页面分成信息型、交易型、导航型,再决定是否让它进入索引池。
二、普通分页怎么做:最稳妥、最可控
页面职责要分清
普通分页适合做成三层职责:
- 第 1 页:入口页,承担主题概览和分发
- 第 2 页及以后:承担深层内容发现
- 每一页:都要有稳定 URL、独立内容和可抓取链接
URL 设计要统一
建议遵守这几条:
- 一套列表只保留一种 URL 形态,避免 /category/、/category?page=1、/category/index.html 同时存在
- 如果 page=1 和根路径同时存在,必须 301 收敛到一种形式
- page=2 以后使用稳定参数或路径段,例如 ?page=2 或 /page/2/
- 排序参数和分页参数不要混乱叠加,否则会制造大量重复页
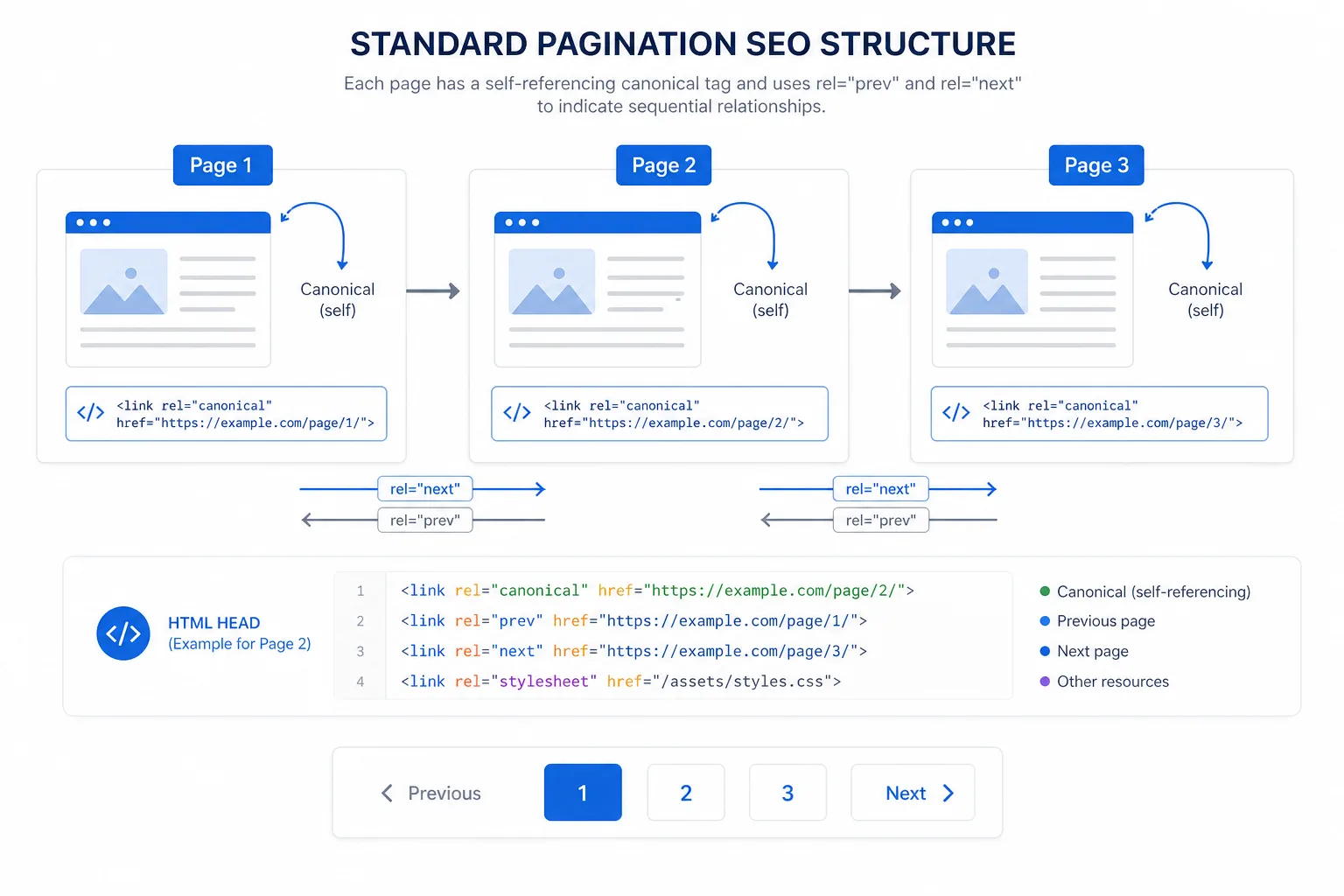
canonical 的原则是自指,不是都指向第一页
对于可索引的分页,最常见的做法是:
- 第 1 页 canonical 指向自己
- 第 2 页、第 3 页……也分别 canonical 指向自己
- 只有在页面内容实质重复时,才考虑合并或 noindex
很多团队会把所有分页都 canonical 到第 1 页,这会让深层页的独立价值被稀释,甚至影响发现路径。如果第 2 页以后仍然展示不同内容,就不要把它们统一 canonical 到第一页。
prev/next 现在怎么理解
Google 目前不再把 rel='prev/next' 作为索引信号;你可以保留它,作为语义标记和其他系统的兼容支持,但不要依赖它来解决索引问题。真正起作用的还是:
- HTML 里的可抓取链接
- 自指 canonical
- 站点地图
- 内部链接结构
- 页面内容差异
可复制示例 1:普通分页模板
<link rel='canonical' href='https://example.com/products?page=2'>
<link rel='prev' href='https://example.com/products?page=1'>
<link rel='next' href='https://example.com/products?page=3'>
<nav class='pagination' aria-label='分页'>
<a href='/products?page=1'>上一页</a>
<a href='/products?page=1'>1</a>
<a href='/products?page=2' aria-current='page'>2</a>
<a href='/products?page=3'>3</a>
<a href='/products?page=3'>下一页</a>
</nav>
这个模板的作用是:让每一页都成为独立 URL,同时保留清晰的上一页、下一页和页码入口。即使 Google 不再使用 rel='prev/next' 作为信号,代码里保留它仍然有助于规范化维护。
三、无限滚动、加载更多与普通分页的关系
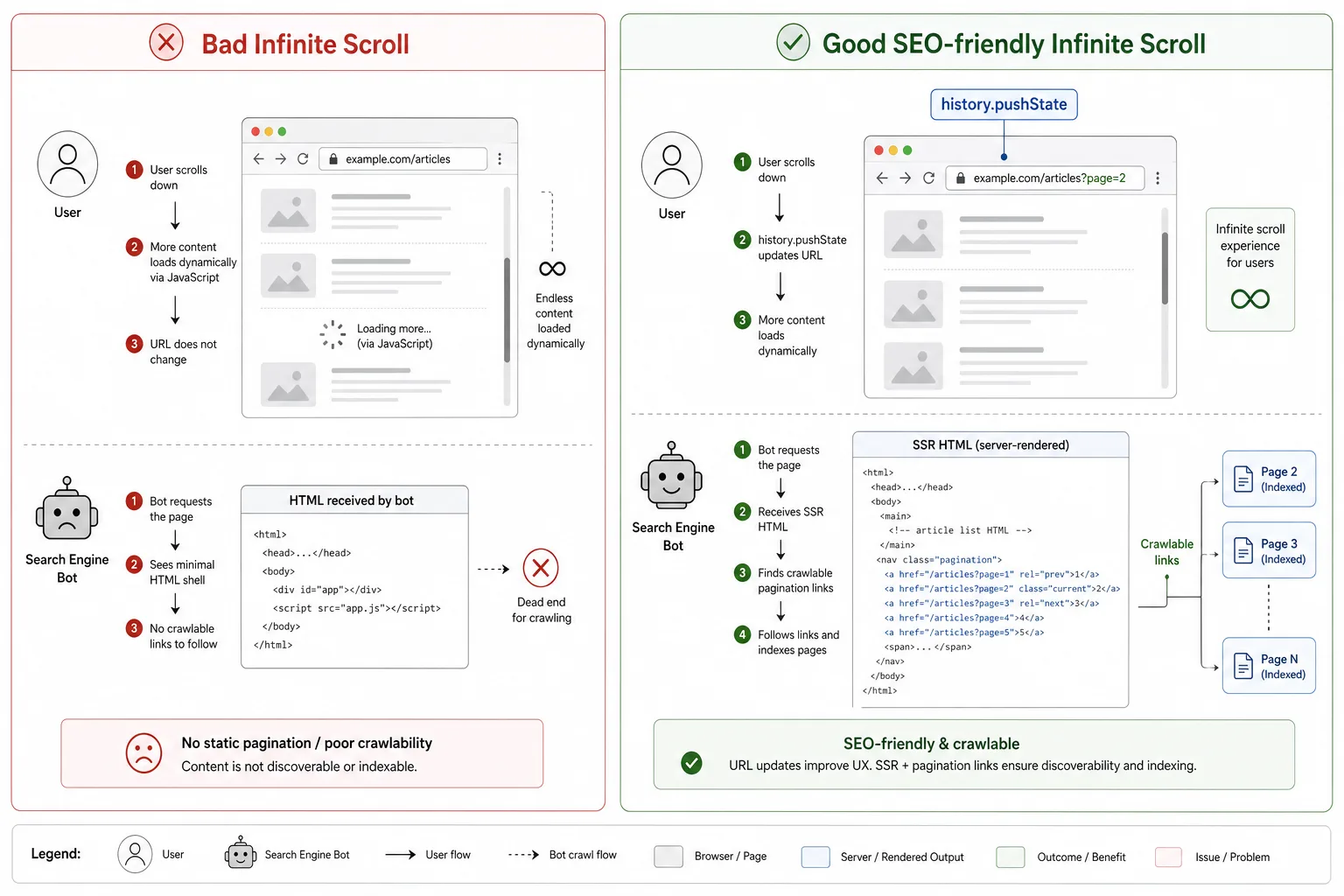
先说结论:无限滚动可以做,但不能只有无限滚动
SEO 视角下,真正可接受的是“前端无限滚动 + 后端分页实体”,而不是“一个 URL 无限加载所有内容”。如果只有滚动事件和 API 调用,没有稳定页面 URL,那么深层内容很难被稳定发现和索引。
推荐实现方式
正确做法通常是这样:
- 首屏由 SSR 输出第 1 页内容
- 页面里保留第 2 页、第 3 页的真实链接
- 用户滚动时加载下一页内容
- 加载后用 history.pushState 更新当前 URL
- 仍然提供一个可点击的“加载更多”或“进入第 2 页”链接
反例不要这样做
以下做法风险很高:
- 只提供 /api/list?page=2,页面本身没有分页 URL
- 无限滚动只依赖 JS,关闭脚本后无法到达深层内容
- 页面底部没有可抓取的 <a href='...'> 链接
- 所有内容都堆在一个 URL 下,无法区分页面职责
可复制示例 2:加载更多 + URL 更新
<div id='list'>
<!-- 由 SSR 输出 page 1 -->
</div>
<a id='loadMore' href='/products?page=2' data-next='/products?page=3'>加载更多</a>
<noscript>
<a href='/products?page=2'>进入第 2 页</a>
</noscript>
<script>
const btn = document.getElementById('loadMore');
btn.addEventListener('click', async (e) => {
e.preventDefault();
const res = await fetch(btn.href, { headers: { 'X-Requested-With': 'fetch' } });
const html = await res.text();
document.getElementById('list').insertAdjacentHTML('beforeend', html);
const next = btn.dataset.next;
if (next) {
btn.href = next;
history.pushState({}, '', btn.href);
} else {
btn.remove();
}
});
</script>
这个方案的关键不是按钮,而是按钮背后有真实的分页 URL。也就是说,“加载更多”只是 UI 包装,底层仍然要保留可抓取的分页实体。
四、canonical、noindex 与 robots:分别什么时候用
canonical:用来统一重复,不是用来消灭深层页
对于分页列表,canonical 的目标是统一同一内容的多种访问方式,而不是把所有深层页都压回第一页。你可以这样处理:
- 规范化同页不同参数顺序
- 统一尾斜杠和非尾斜杠
- 统一 page=1 和根路径
- 保留每个有独立内容的分页页自指 canonical
noindex:适合搜索结果页、低价值组合页、空结果页
如果一个页面只是用户查询的即时结果,或者组合参数太多、内容太薄,通常更适合 noindex,follow。这样可以让搜索引擎继续沿链接发现其他页面,但不把这些低价值页放进索引。
robots.txt:不要乱封你还想让它被发现的页面
如果你把分页 URL 直接挡在 robots.txt 里,搜索引擎连页面都看不到,canonical 和内部链接信号也会失去作用。原则是:
- 想索引的分页,不要封
- 不想索引的搜索结果页,可以用 noindex,follow
- 极大规模的参数噪音,才考虑更强的抓取限制
可复制示例 3:给站内搜索结果加 noindex
location ^~ /search {
add_header X-Robots-Tag 'noindex,follow' always;
}
这个配置适合站内搜索结果页、零结果页或低价值查询页。它比单纯靠前端 meta 更稳,因为服务端层就明确了索引策略。
官方参考再补两篇

五、不同行业怎么落地
电商:商品列表页要让深层 SKU 可被发现
电商最容易出问题的是筛选和排序。
建议:
- 商品类目页使用普通分页或加载更多
- 每页保留稳定数量的商品卡片
- 颜色、价格、品牌等筛选组合只开放少量可索引落地页
- 排序页通常不索引,避免制造大量重复 URL
例子:
- /shoes?page=2 这类分类分页应可索引
- /shoes?sort=price_asc 这类排序页通常不索引
- /shoes?brand=nike&color=black&page=2 这种组合要谨慎控制
SaaS:案例库、模板库、帮助中心都适合分页
SaaS 网站常见问题不是内容太少,而是内容分布太散。
建议:
- 案例库、模板库、资源中心用分页保证深层内容可发现
- 重要主题页保持静态可索引,分页页做补充发现
- 如果是产品更新日志或帮助中心列表,分页比纯无限滚动更利于长期维护
例子:
- “客户案例”列表第 1 页做概览,第 2 页以后继续承载新增案例
- “模板库”如果有上百个模板,必须有稳定分页 URL
B2B:线索型页面要控制薄页和重复页
B2B 网站经常有行业方案、白皮书、活动回顾和案例列表。
建议:
- 行业方案页是核心页,列表分页只是补充入口
- 案例列表页分页要保留独立 URL,方便长尾项目被发现
- 如果某一类页面长期只有少量内容,宁可合并,不要硬做无限滚动
例子:
- “制造业解决方案”页面可以有分页案例列表
- “白皮书资源库”可以分页,但低价值标签页不要乱开放索引
本地服务:目录和城市页要把抓取路径设计清楚
本地服务最常见的是城市页、商家目录页、服务目录页。
建议:
- 城市/服务的核心落地页独立索引
- 商家目录页使用分页暴露更多商家
- 地图视图、距离排序、实时状态筛选一般不索引
- 不要把“城市 + 服务 + 排序 + 距离 + 营业中”全部做成可索引组合
例子:
- “上海办公室装修公司”是核心页
- 该页下的商家列表可以分页
- “按评分排序”通常只是用户筛选,不应成为主索引页
六、上线前检查清单
抓取路径是否完整
检查这几个点:
- 第 1 页能否直接链接到第 2 页及以后
- 深层页是否能从 HTML 链接到达,而不是只靠 JS 触发
- 站点地图中是否包含重要分页 URL
- 重要分页页是否在三次点击内可达
索引控制是否一致
检查这几个点:
- 页面 canonical 是否与实际 URL 一致
- page=1 是否和根路径统一
- 搜索结果页是否已经 noindex,follow
- 过滤组合是否存在重复和薄页风险
- 不想索引的参数页是否被错误加入 sitemap
长期维护是否可监控
上线后不要只看收录数,要看:
- 日志里 page 2 以后的抓取是否稳定
- Search Console 里是否出现大量重复、已抓取未编入索引或规范化冲突
- 分页模板是否被前端改造后失去可抓取链接
- 内容增长后分页是否需要拆分或合并
如果你要决定“某个分页页到底值不值得长期保留在索引里”,可以直接用 ROI 决策工作台 把流量潜力、维护成本和重复风险放到一起算。
如果模板要批量生成分页页标题、导语或摘要,先用 AI 风险检测工具 预先检查重复风险,避免新模板上线后把薄页问题放大。
七、最常见的错误
错误 1:page 2、page 3 全部 canonical 到 page 1
这会让深层页的独立价值被压掉。除非页面内容高度重复,否则不要这样做。
错误 2:无限滚动只有一个 URL
这会让深层内容很难被发现,也不利于外链落地和分享。
错误 3:站内搜索结果页被大面积收录
搜索结果页通常重复多、长尾多、价值低。默认应 noindex,follow。
错误 4:分页链接只有按钮,没有 href
纯按钮可以提升体验,但 SEO 需要真实链接。没有 href,就没有稳定 crawl path。
错误 5:参数组合无限增长
分页、排序、筛选、城市、标签混在一起,最后会变成一个不可维护的索引池。要提前定义:哪些组合可索引,哪些只服务用户不服务搜索引擎。
最后一句
分页 SEO 的本质,是把“列表展示”升级成“内容发现系统”。当你能明确每一页的职责、URL、canonical 和抓取路径时,普通分页、加载更多和无限滚动都可以成为可控方案,而不是风险来源。
下一课可以继续看: