SEO 自动化怎么做:批量监控、规则检查与告警
SEO 自动化怎么做:批量监控、规则检查与告警
人工巡检 SEO 的最大问题不是“做不做”,而是“做不完、做不准、做不快”。一旦站点页面量上来,标题、canonical、noindex、状态码、结构化数据、内链和核心页面流量异常就会以模板级问题的形式集中爆发。正确做法不是把检查交给人,而是把它做成可执行的规则、可复用的数据源和可追踪的告警链路。

一、先定义监控对象:监什么,不监什么
核心页面分层
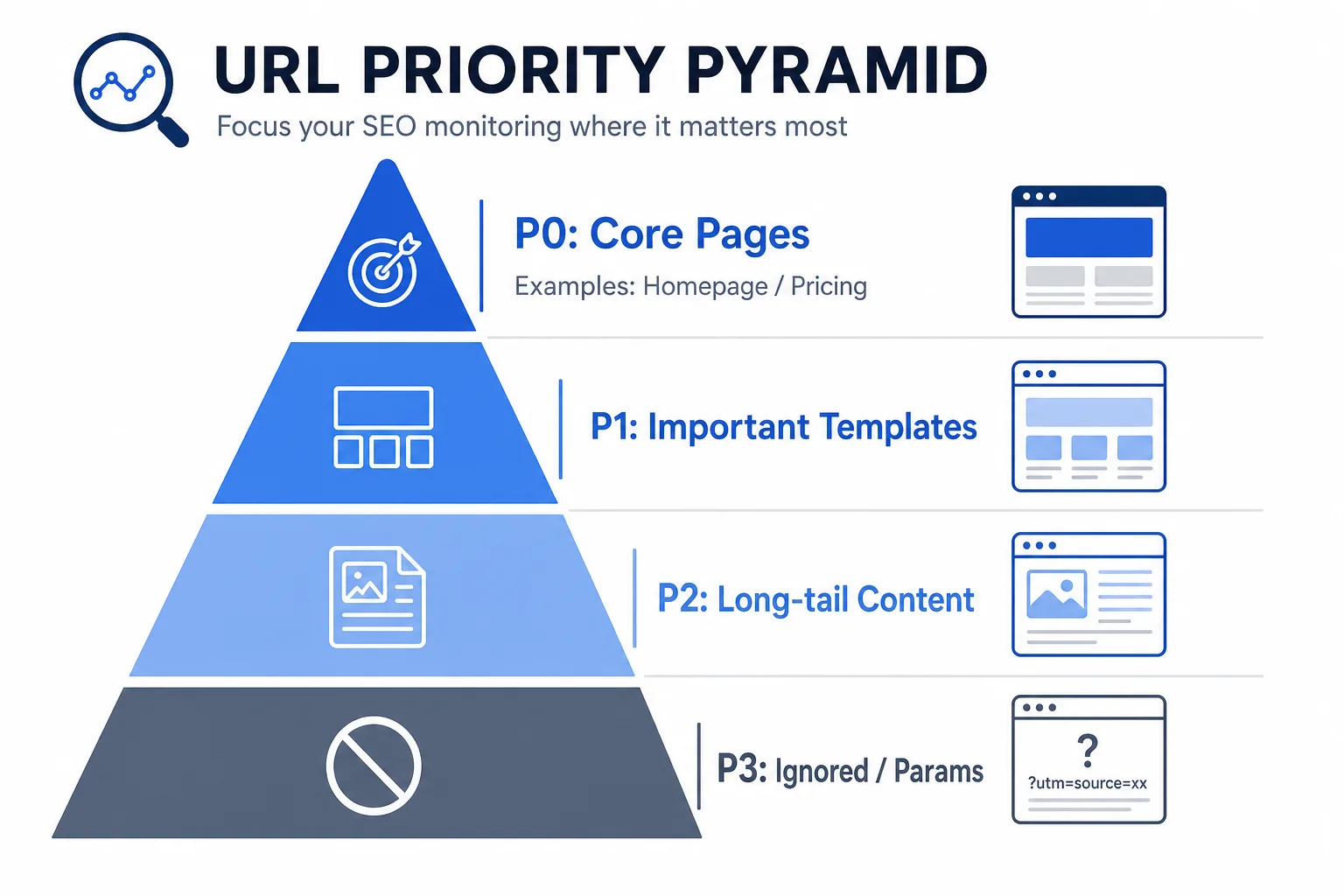
不要一上来就全站同等对待。建议把 URL 先分成四层:
- P0:首页、核心类目页、核心落地页、价格页、转化页、门店页
- P1:重要模板页,如商品详情、解决方案页、城市页、功能页
- P2:长尾内容页、帮助文档、FAQ、博客页
- P3:测试环境、重复内容、可被忽略的过滤页和参数页
监控范围越大,越要先做分层。P0 和 P1 需要全量监控;P2 适合模板抽样;P3 只做策略性放行或黑名单控制。
用搜索意图和 ROI 决定优先级
页面很多时,先解决“先盯谁”比“怎么盯”更重要。可以先用 意图识别工具 给页面模板打搜索意图标签,再用 ROI Decision Workbench 计算监控优先级;如果内容生产高度依赖生成式流程,也建议用 AI Risk 预先标记高风险页面,避免批量低质内容放大 SEO 风险。
四类业务的监控重点
- 电商:类目页、商品页、筛选页、库存状态、价格页、库存告罄页
- SaaS:定价页、试用页、功能页、对比页、文档页、登录前转化页
- B2B:解决方案页、行业页、案例页、白皮书页、线索页
- 本地服务:城市页、门店页、服务页、营业时间页、NAP 一致性页面
二、规则引擎应该检查什么
标题、canonical、noindex、状态码、结构化数据、内链
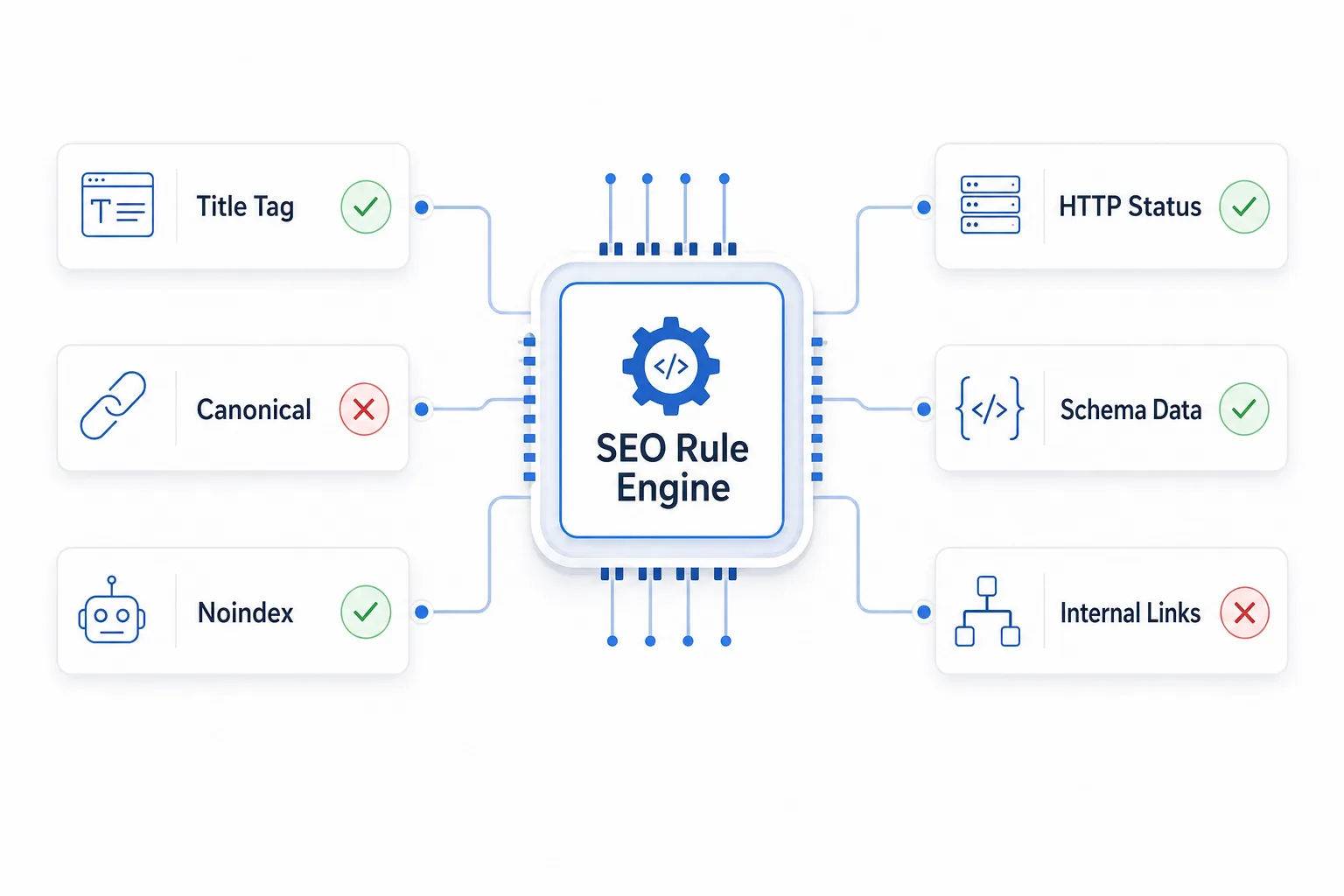
建议把 SEO 规则写成机器可执行的判定条件,而不是写进文档后靠人工记忆。最少要覆盖以下项目:
- 标题:是否缺失、是否重复、是否过短或过长、是否与模板冲突
- canonical:是否缺失、是否自指、是否错误指向其他域名或错误参数页
- noindex:核心页是否被误加 noindex,是否被 HTTP Header 或 meta robots 覆盖
- 状态码:是否出现 4xx/5xx,是否存在过长重定向链
- 结构化数据:是否缺失、是否报错、是否与页面类型不匹配
- 内链:是否孤儿页、是否深度过深、是否关键页面被降权
- 核心页面异常:点击、展示、收录、排名、转化是否出现断崖式波动
canonical、noindex 和结构化数据的处理口径,可以直接对照公开文档:canonical 参考 Google Search Central 的 consolidate duplicate URLs,noindex 参考 block indexing,结构化数据参考 structured data intro。
规则必须有白名单和例外
不是所有 noindex 都是错,不是所有 canonical 都要自指。你需要先定义允许例外的页面类型:
- 参数过滤页允许 noindex
- 测试环境允许整站屏蔽
- 分页页允许指向规范集合页
- 登录页、注册页、购物车页允许不参与索引
规则设计的关键,不是“尽量严格”,而是“严格地区分正常例外和异常故障”。
一个可维护的规则配置示例
page_priority:
p0: ['homepage', 'pricing', 'top_category', 'top_location']
p1: ['product', 'solution', 'city_landing', 'feature']
p2: ['blog', 'faq', 'docs']
rules:
title_missing:
severity: P1
scope: ['all_indexable']
when: "title == ''"
canonical_bad:
severity: P0
scope: ['p0', 'p1']
when: "canonical_missing or canonical_domain != current_domain"
noindex_on_core_page:
severity: P0
scope: ['p0', 'p1']
when: "meta_robots contains 'noindex' or x_robots_tag contains 'noindex'"
status_error:
severity: P0
scope: ['all']
when: "status >= 500 or (status in [301, 302] and redirect_chain > 1)"
schema_invalid:
severity: P2
scope: ['product', 'software', 'localbusiness', 'faq', 'breadcrumb']
when: "schema_valid == false"
internal_links_drop:
severity: P2
scope: ['all']
when: "inlinks < baseline_inlinks * 0.7"
这个配置的作用是把规则、严重级别和页面范围拆开:页面范围决定是否生效,severity 决定谁接警,when 决定是否触发。
三、数据源:单一来源不够,必须合并
监控数据至少要来自六类系统
要做批量监控,不能只靠爬虫。推荐把这些来源一起纳入:
- Sitemap 和 CMS/数据库:拿到全量 URL、模板类型、发布状态
- 爬虫:拿到标题、canonical、meta robots、结构化数据、内链、状态码
- 服务器日志:确认真实抓取、状态码、重定向、异常峰值
- Search Console:点击、展示、索引覆盖、抓取异常
- Analytics/埋点:转化、跳出、停留、收入或线索变化
- 监控系统:站点可用性、API 可用性、模板发布回归
建议统一一张监控表
最少要有这些字段:
- url
- template_type
- page_priority
- status_code
- canonical_url
- noindex_flag
- title_hash
- schema_valid
- inlinks_count
- clicks_7d
- impressions_7d
- conversion_7d
- last_seen_at
这张表的意义是把“页面技术状态”和“业务结果”放到同一张口径里,便于做批量对比和异常定位。
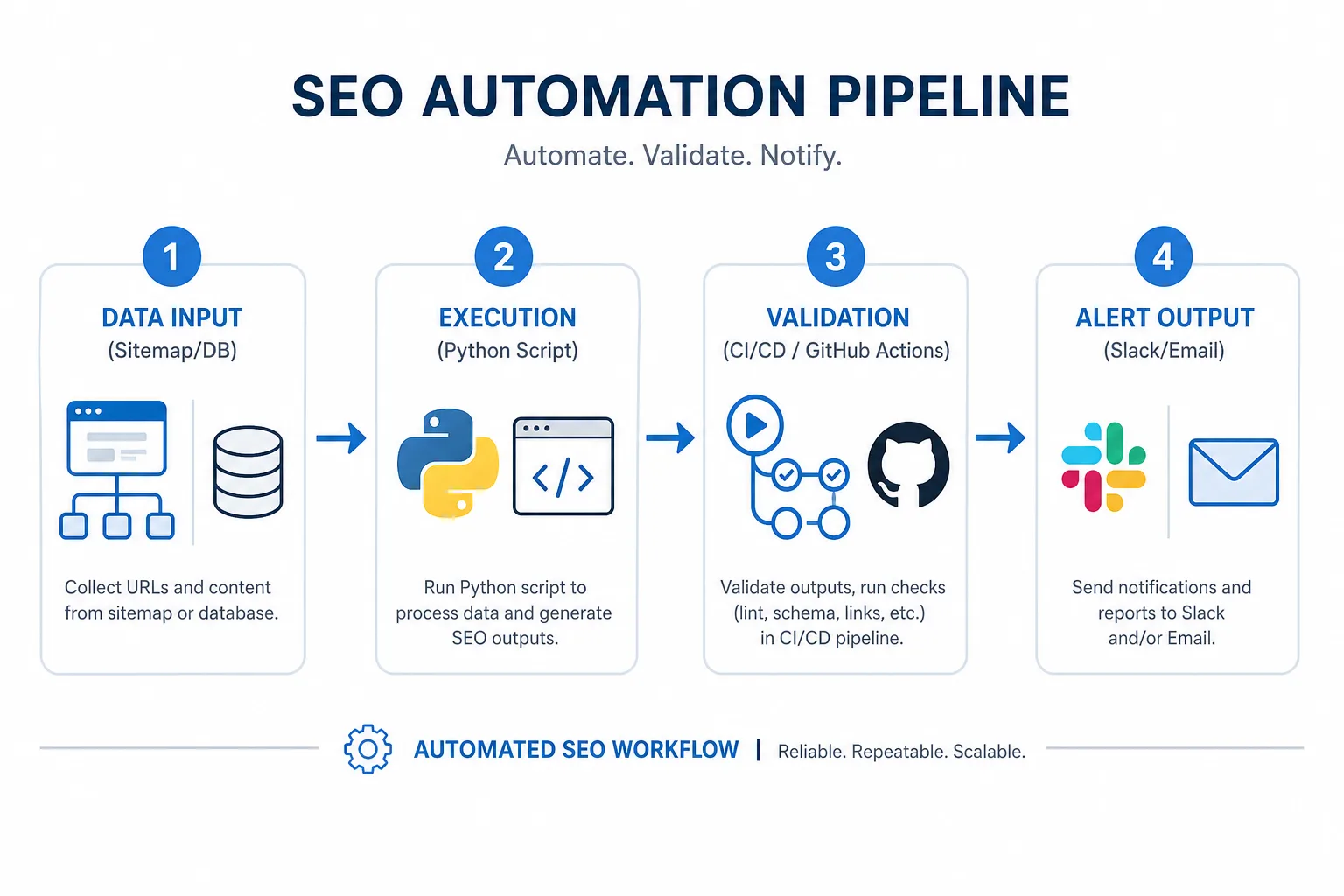
四、自动化实现:脚本 + CI + 定时任务
监控脚本负责做什么
脚本的职责不是“爬全站”,而是“按规则采样、判定、输出告警”。建议至少包含以下步骤:
- 从 sitemap、数据库或 URL 清单读取页面
- 按模板和优先级分组
- 抓取页面并提取 title、canonical、robots、状态码、schema、内链数
- 与基线比较,判断是否异常
- 输出到 JSON/CSV,并发送到告警系统
Python 监控脚本示例
import requests
from bs4 import BeautifulSoup
HEADERS = {'User-Agent': 'SEO-Monitor/1.0'}
def check_url(url):
r = requests.get(url, timeout=10, allow_redirects=True, headers=HEADERS)
soup = BeautifulSoup(r.text, 'html.parser')
title = soup.title.text.strip() if soup.title and soup.title.text else ''
canonical = soup.find('link', rel='canonical')
robots = soup.find('meta', attrs={'name': 'robots'})
robots_content = robots.get('content', '').lower() if robots else ''
return {
'url': url,
'status_code': r.status_code,
'title_ok': bool(title),
'canonical_ok': bool(canonical and canonical.get('href', '').split('?')[0]),
'noindex': 'noindex' in robots_content,
}
if __name__ == '__main__':
for u in ['https://example.com/']:
result = check_url(u)
print(result)
这个脚本的作用是验证最基础的页面健康度。生产环境里,你需要把结果写入表格或时序库,再交给告警系统处理,而不是直接打印到控制台。
CI 和定时任务怎么配合
CI 适合做“发布前拦截”,定时任务适合做“发布后巡检”:
- CI:模板、代码、SEO 配置变更后,自动跑样本 URL 检查,失败则阻止合并
- 定时任务:每天或每小时全量/分层巡检,发现异常后发送告警
GitHub Actions 定时巡检示例
name: seo-monitor
on:
schedule:
- cron: '15 2 * * *'
pull_request:
paths:
- 'templates/**'
- 'seo-rules.yml'
- 'scripts/**'
jobs:
crawl-and-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.11'
- run: pip install -r requirements.txt
- run: python scripts/seo_monitor.py --config seo-rules.yml --sample 200
- if: failure()
run: curl -X POST ${{ secrets.ALERT_WEBHOOK }} -d '{'"'"'level'"'"':'"'"'P0'"'"','"'"'msg'"'"':'"'"'SEO regression detected'"'"'}'
这个配置同时覆盖了两件事:PR 阶段拦截模板回归,定时任务做每日巡检。这样可以把“上线后才发现”前移到“合并前就发现”。
五、告警等级怎么定:别让告警淹没团队
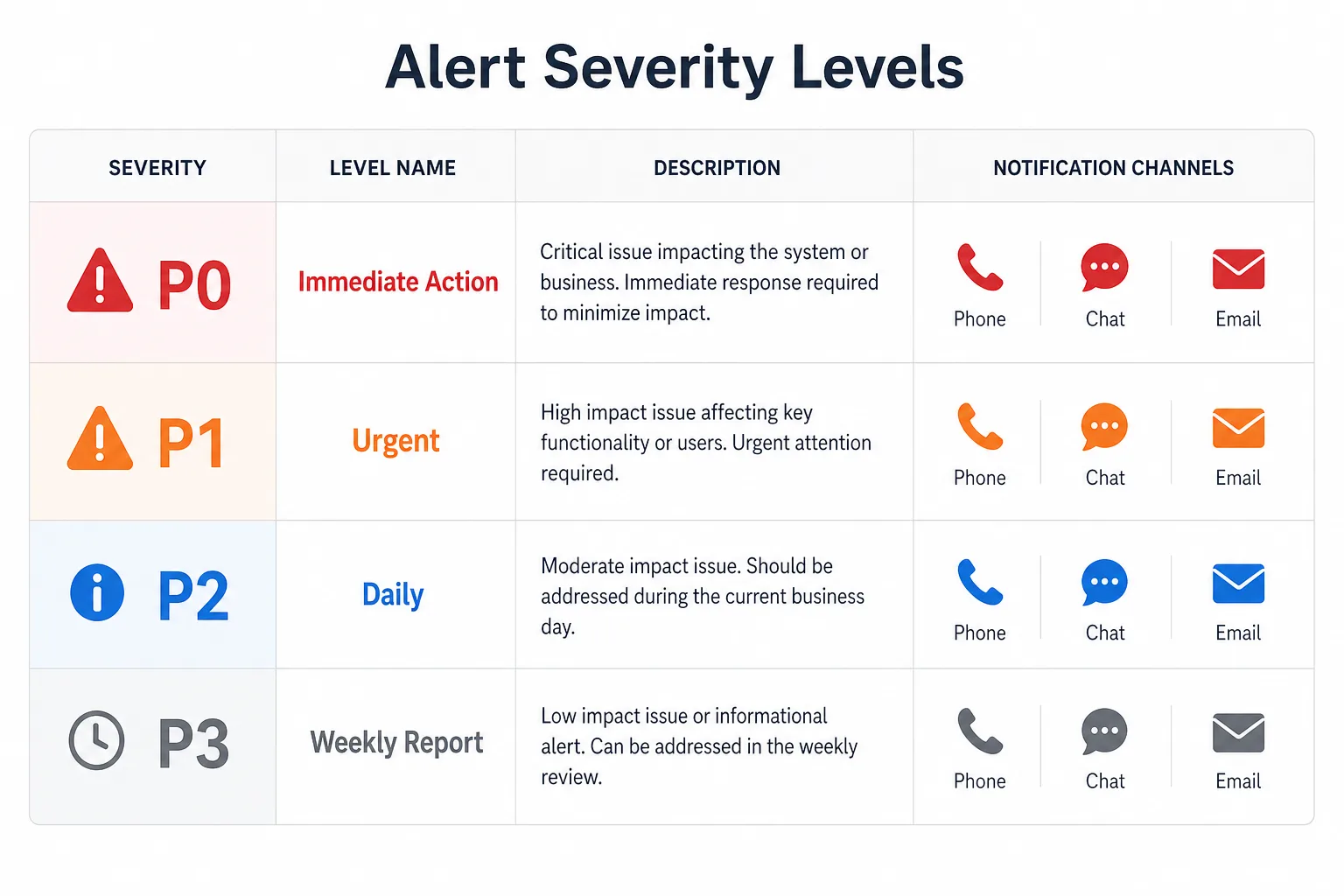
建议的 P0 到 P3 分级
| 等级 | 触发条件 | 处理时限 | 通知方式 |
|---|---|---|---|
| P0 | 首页、价格页、核心类目页被 noindex、canonical 错指、整站 5xx、robots 误封 | 15 分钟内 | 电话 + IM + 工单 |
| P1 | 重要模板大面积异常,预计影响收录或流量 10%–30% | 1 小时内 | IM + 邮件 |
| P2 | 单模板、单业务线、单城市页异常,影响有限 | 当天 | IM |
| P3 | 个别标题重复、少量结构化数据缺失、边缘页面异常 | 日报或周报 | 报表 |
告警要做去重、聚合和抑制
否则你会得到一堆重复消息:同一模板的 500 个 URL 同时报错,最后没人看。
建议这样处理:
- 按模板聚合,而不是按 URL 刷屏
- 同一问题在 30 分钟内只推送一次
- 恢复后自动关闭告警并保留恢复时间
- 对已知维护窗口做告警抑制
标准处置流程
- 先确认是单页、模板还是全站问题
- 对比最近一次发布、配置变更、CMS 变更
- 必要时回滚模板或修复规则
- 修复后立即重抓样本验证
- 复盘并把这次事故转成自动测试用例
六、不同业务怎么落地
电商:盯住类目页、商品页和筛选页
电商最容易出的问题是批量参数页污染索引、商品下架后状态异常、canonical 指向错误类目页。
重点规则:
- 商品页必须有自指或正确 canonical
- 筛选参数页默认 noindex,除非明确做 SEO 落地页
- 下架商品要走 301、替代推荐或保留页策略,不能直接 404 批量放飞
- Product、Breadcrumb、Offer 结构化数据要持续校验
SaaS:盯住定价页、试用页和功能页
SaaS 的核心风险是转化页被误加 noindex,或者比较页、功能页 canonical 指错。
重点规则:
- pricing、trial、demo 页必须纳入 P0
- docs 和 help 页可以低优先级,但结构化数据和内链要稳定
- 软件类页面的 schema 建议按 SoftwareApplication、FAQ、Breadcrumb 进行校验
- 如果产品模板频繁改版,CI 必须做模板回归测试
B2B:盯住解决方案页和案例页
B2B 更容易出现的问题不是技术崩溃,而是“页面被做成了一堆重复模板”。
重点规则:
- 行业页、解决方案页、案例页必须有清晰意图和差异化标题
- 关键页面必须能从文章页和导航页获得足够内链
- 线索页不能被误设 noindex,表单页要做可用性监控
- 案例页适合加入 Article、Breadcrumb、Organization 相关校验
本地服务:盯住城市页、门店页和营业信息
本地服务最大的问题是信息不一致:地址、电话、营业时间、地图、门店状态不同步。
重点规则:
- LocalBusiness schema 的名称、地址、电话要和站内保持一致
- 门店页 404、门店关闭后未回收、城市页 canonical 错指,都要告警
- 营业时间变更后,必须同步到页面与结构化数据
- 分店矩阵建议按城市和业务线聚合监控,避免单页失控
七、把自动化做成事故预防系统
最小可行方案
如果你现在还没有系统,不要追求一步到位,先做一个 30 天可上线的版本:
- 第 1 周:梳理 URL 清单、模板分类、页面优先级
- 第 2 周:写规则配置,先覆盖 title、canonical、noindex、状态码
- 第 3 周:接入爬虫脚本和定时任务,输出日报和告警
- 第 4 周:接入 CI,给模板变更加“SEO 回归门禁”
成功标准
自动化是否有效,不看“检查了多少项”,看“减少了多少事故”:
- 核心页 noindex 被发现的时间从几天缩短到几分钟
- 模板级 canonical 错误在上线前被阻断
- 404/5xx 的发现从人工巡检变成自动告警
- 复盘后新增的规则能自动进入 CI,避免重复事故
最后一个建议
SEO 自动化不是为了替代人,而是为了把人的时间从“排查低级错误”释放到“优化结构、内容和增长机会”上。你真正要建立的,不是一套脚本,而是一套可验证、可告警、可回滚的 SEO 事故预防体系。
下一课可以继续看: