SEO 日志分析怎么做:抓取频次、浪费抓取与异常 URL
SEO 日志分析怎么做:抓取频次、浪费抓取与异常 URL
SEO 日志分析不是“看 UA 和状态码就下结论”,而是把服务器日志、边缘日志、页面模板和索引结果放到同一口径里,回答三个问题:搜索引擎到底抓了什么、抓得是否浪费、重要页面有没有被足够频繁地回访。
如果你负责技术 SEO、后端或运维,这篇文章的目标很直接:用日志把抓取行为量化,找出异常 URL、404/5xx、参数污染、抓取预算浪费和关键页面抓取不足,并把结果自动化到日报、告警和事故预防里。

一、先统一数据口径:日志里必须保留什么字段
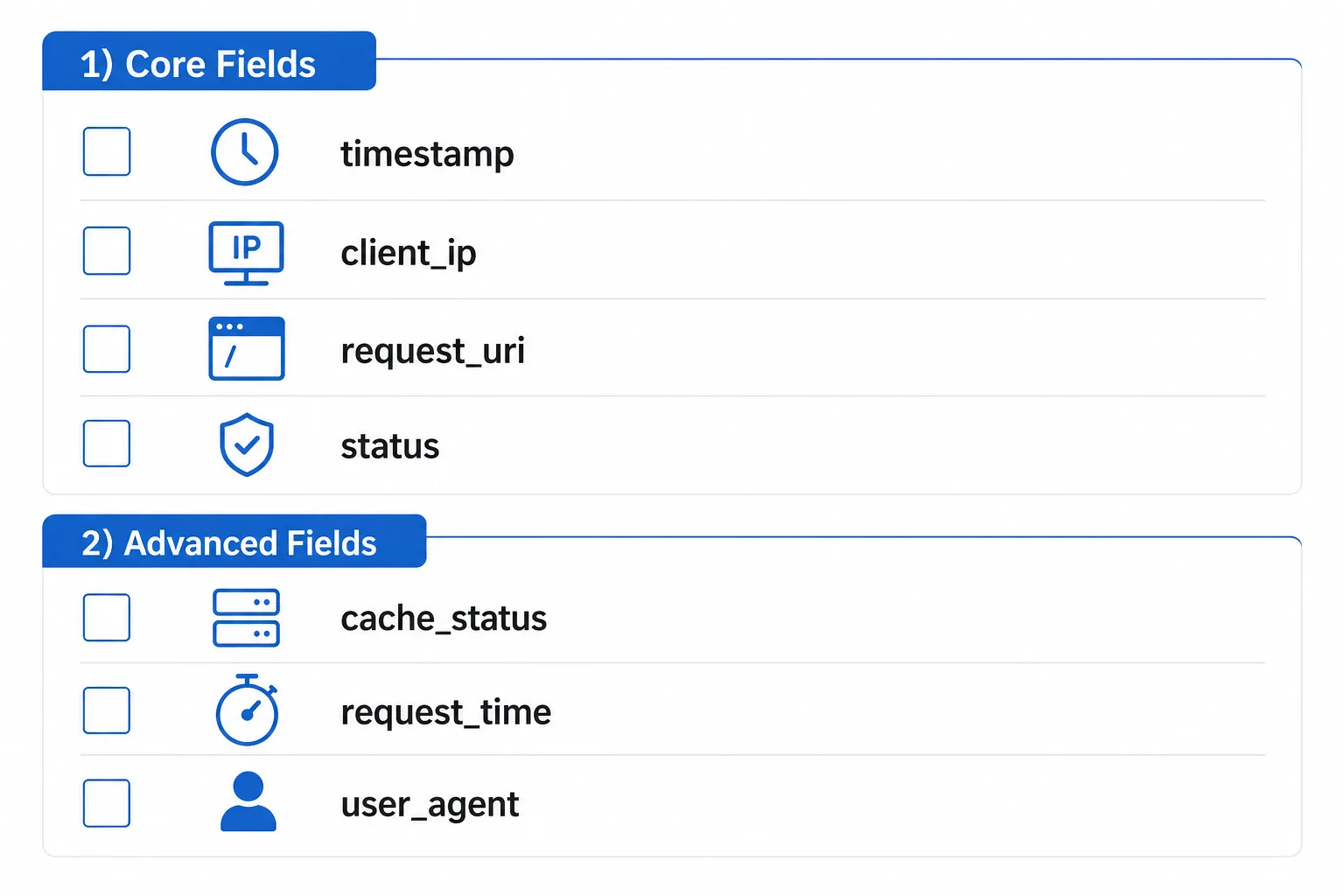
1.1 最小可用字段
你至少要拿到这些字段:
timestamp:精确到秒或毫秒,后续判断抓取频次、峰值和再抓取间隔都靠它。client_ip/remote_addr:判断抓取来源,后面要做 Googlebot/Bingbot 反向解析验证。x_forwarded_for/cf-connecting-ip/x-real-ip:如果站点有 CDN、WAF 或反代,这个字段决定你拿到的是不是原始访问者。host:多站点、多子域时非常关键。method:通常以GET为主,HEAD也要单独统计。request_uri:路径 + 查询串,是识别异常参数、重复抓取和搜索结果页的核心。status:200、301、404、410、5xx 要分开看。bytes_sent:排查抓取是不是在吃大文件、图片或下载资源。request_time/upstream_response_time:判断服务器慢不慢,慢到什么程度。referer:有时能反推出内部链接结构和错误来源。user_agent:只能作为辅助,不能单独当作 bot 证据。
如果你有条件,还应该加上:
cache_status:HIT / MISS / BYPASS,方便判断边缘缓存是否影响抓取。scheme:http/https,用于检查协议迁移残留。country/asn:跨地域站点有价值。response_length或content_type:排查 bot 是否在抓取非页面资源。
1.2 采集优先级
优先拿这些日志源:
- CDN / WAF / 边缘层日志
- 负载均衡日志
- Nginx / Apache 源站日志
- 应用层日志
原因很简单:bot 先到边缘层,真实流量也先经过边缘层。只看源站日志,容易漏掉被 CDN 缓存拦截的抓取;只看 CDN 日志,又可能看不到应用层的 5xx 根因。实践里最好两层都保留,至少能对得上同一请求链路。
1.3 公开口径建议
日志分析最好和搜索引擎官方口径对齐:
- Google 的抓取预算说明:large site managing crawl budget
- Googlebot 验证方法:verifying Googlebot
- Bingbot 验证方法:How to verify that Bingbot is crawling your site
- Nginx 日志字段说明:ngx_http_log_module
二、Googlebot 和 Bingbot 识别:不要只看 User-Agent
2.1 识别原则
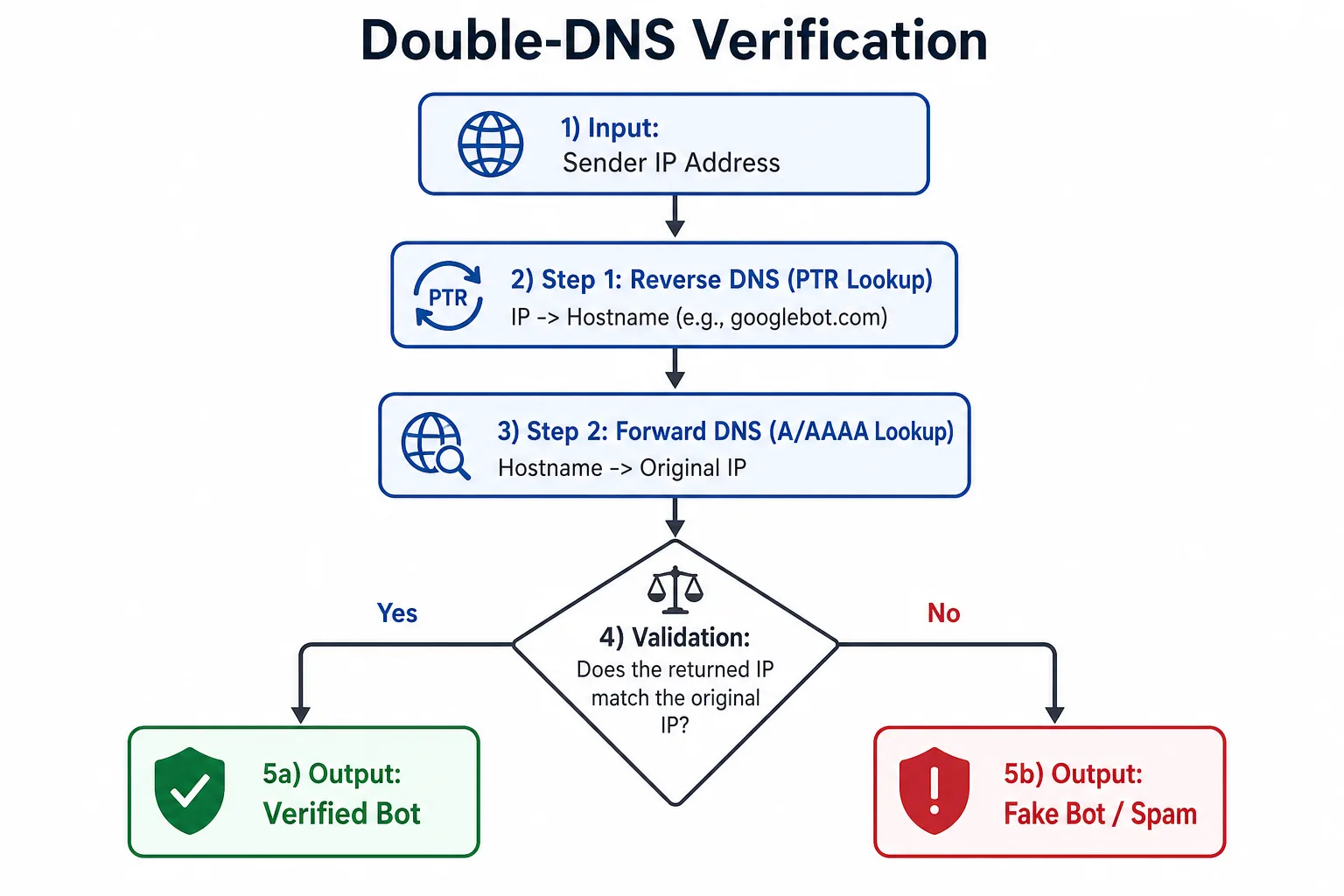
User-Agent 只能做第一层筛选,不能做最终判定。真实抓取机器人要同时满足两个条件:
- UA 看起来像 Googlebot / Bingbot
- 访问 IP 通过官方的反向 DNS 与正向 DNS 验证
Google 的典型校验逻辑是:
- 反向解析 IP,域名应落在
googlebot.com或google.com后缀下; - 再做正向解析,确认域名解析回来的 IP 仍然是同一个地址。
Bingbot 同理,常见后缀是 search.msn.com。如果 UA 命中但 DNS 校验失败,就不要当作真实 bot,而应当记为可疑爬虫或伪装请求。
2.2 落地规则
建议在日志处理层新增两个字段:
bot_family:googlebot、bingbot、otherbot_verified:true/false
这样后面的统计就不会把伪装流量混进来。对于高流量站点,建议把 DNS 验证结果缓存 24 小时,避免每条日志都做实时解析拖慢处理。
2.3 实战判断
如果你看到下面这种情况,就要警惕:
- UA 里写着 Googlebot,但 IP 不属于 Google 官方网段
- 某个机房 IP 反复扫全站,状态码正常但行为像爬虫
- 同一 IP 同时请求首页、接口、图片、站内搜索页,且频次异常高
这类流量常见于竞品抓取、数据采集器、参数爆炸测试,不能直接并入搜索引擎抓取分析。
三、抓取频次怎么看:先看“抓了多少”,再看“抓了什么”
3.1 必看四个频次指标
建议按天、小时、目录、模板四个层级同时看:
- 总抓取量:bot 每天总请求数
- 独立 URL 数:去重后的抓取 URL 数
- 再抓取间隔:同一重要页面两次被抓的时间差
- 状态码分布:200、3xx、4xx、5xx 占比
只看总量很容易误判。比如 bot 请求数上涨,不一定是好事;如果上涨来自大量参数 URL、分页和搜索页,通常说明抓取预算在浪费。
3.2 适合技术团队的判断口径
你可以把抓取频次拆成三个问题:
- 搜索引擎每天抓了多少次?
- 这些请求覆盖的是不是重要页面?
- 这些页面的再抓取间隔是否符合更新频率?
例如:
- 首页、核心分类页、产品详情页、核心文档页,应该有稳定回访
- 低价值的参数页、内部搜索结果页、重复分页页,不应该占太多抓取量
- 如果重要页面更新后 72 小时仍没有再次抓取,就要检查内链、站点地图、响应速度和服务器错误
3.3 抓取预算不是固定配额
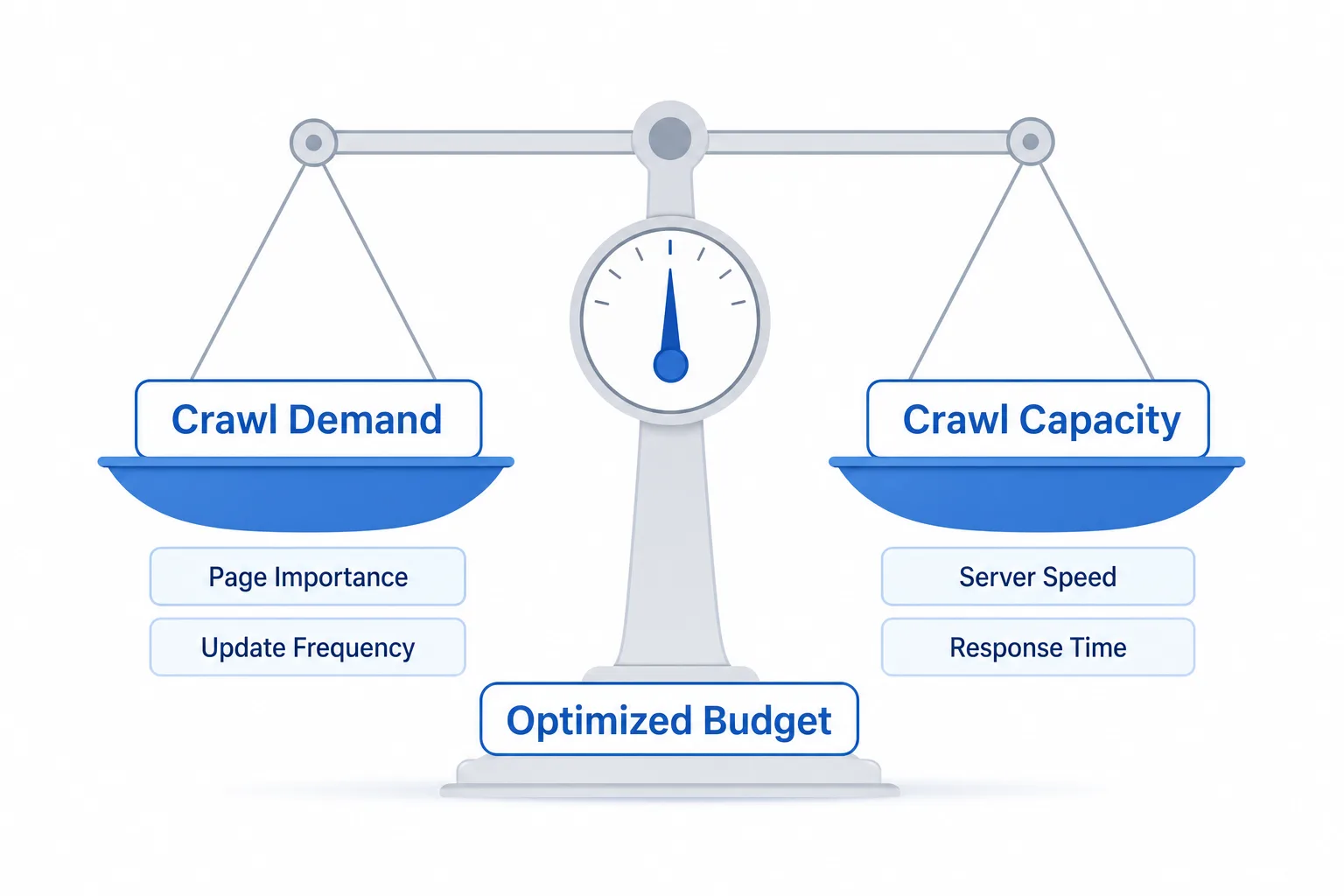
Google 官方没有公开固定的“每天多少次抓取”公式。更实用的理解是:crawl demand 乘以 crawl capacity。
crawl demand:页面重要性、更新频率、内链权重、历史表现crawl capacity:服务器性能、响应时间、稳定性、站点规模
所以,抓取频次异常时不要只问“bot 为什么没来”,还要问“为什么它更愿意抓这些页面”。
四、浪费抓取与异常 URL:最常见的 4 类模式
4.1 电商站:参数、筛选、分页最容易吃掉预算
电商站最典型的浪费抓取来源是 faceted navigation:
?sort=price_asc?color=red?size=m?brand=xxx?page=2?price=100-500
如果这些参数组合过多,就会产生海量近似 URL。日志里常见的症状是:
- 200 页面很多,但大部分是重复列表页
- 核心 SKU 页抓取频次反而偏低
- 站内搜索结果页被反复抓取
- 404/5xx 集中在已下架商品和失效筛选组合
处理原则:
- 保留真正有搜索价值的着陆页
- 对无差异参数做 canonical、noindex 或参数收敛
- 站内搜索结果页默认不让搜索引擎浪费抓取
- 分页页码深度过大时要评估是否保留索引价值
4.2 SaaS 站:文档、帮助中心、版本页和追踪参数
SaaS 常见问题不是抓不够,而是抓得太散:
- 文档版本页重复
- 带 UTM 的帮助中心链接被大量抓取
?ref=、?source=、?plan=等参数制造重复内容- 搜索页、标签页、发布说明页形成低价值循环
SaaS 的重点不是单页流量,而是文档体系和功能页是否被稳定回访。你要重点看:
- 产品页、定价页、集成页的再抓取频次
- 文档更新后多久重新被抓
- 是否有大量低价值版本页占用抓取
如果你的文档站内容由自动化生成,建议结合 AI Risk 工具 先识别大规模近似页面,再决定哪些目录要合并、去重或限制索引。
4.3 B2B 站:PDF、案例页和重复入口页
B2B 站点常见的是内容重复但路径不同:
- 同一案例页同时存在 HTML 和 PDF
- 详情页有打印版、下载版、转发版
- 地区页、行业页、解决方案页模板高度相似
- 带追踪参数的询盘链接被爬虫反复命中
B2B 的抓取浪费通常不是单纯参数问题,而是信息架构问题。你要重点检查:
- 是否存在多路径到同一内容
- 是否通过内链把权重导向了低价值页面
- 是否在多个目录发布了相同白皮书或案例
4.4 本地服务站:城市词和门店页重复度高
本地服务站特别容易出现“城市名 + 服务词”的组合爆炸:
/?city=shanghai/?area=pudong/?service=cleaning/?utm_source=map?sort=distance
如果站点用参数动态生成城市页,日志里就会看到大量重复路径、极低内容差异和高频抓取。更合理的做法是:
- 把高价值城市页做成静态可索引落地页
- 低价值筛选参数做规范化或限制索引
- 门店页和服务页保持清晰的层级结构
- 对地图、导航、预约接口与页面 URL 做隔离
4.5 这些 URL 一出现,先列为异常池
建议直接建立异常 URL 规则库,至少包含这些模式:
?sort=?filter=?page=?sessionid=?utm_?ref=searchtagprintfeedapi- 重复斜杠、大小写混乱、末尾斜杠不一致
- 3xx 链式跳转超过 1 次
- 4xx、5xx 在短时间内集中爆发

五、状态码怎么解读:404、5xx 和软 404 都是抓取信号
5.1 200 不是全部正常
200 只能说明返回成功,不代表内容有 SEO 价值。日志里还要看:
- 返回的是不是最终规范页
- 是否通过 JS 才能渲染主要内容
- 是否返回了空壳页、模板页或低内容页
5.2 301 / 302
单次重定向通常没问题,但要防止:
- 301 到 302 再到 200
http -> https -> www -> 末尾斜杠多跳- 老 URL 链条太长
如果 bot 经常访问旧 URL,且链路太长,浪费抓取会很明显。
5.3 404 / 410
404 并不一定是坏事,前提是它们来自已下架、已迁移、已清理的内容。但如果日志显示:
- 某个目录下的 404 持续增长
- 同一批 URL 被 bot 反复请求
- 404 伴随大量内链或站点地图命中
那就是结构性问题,不是单个死链问题。
410 更适合“确定永久删除且不再恢复”的页面。它对搜索引擎传递的信号更明确。
5.4 5xx
5xx 是抓取和索引的硬伤。对 bot 来说,5xx 会直接降低抓取效率,严重时会减少后续访问频率。分析 5xx 时要分三类:
- 峰值型:某个时段全站报错,通常是发布、扩容、依赖故障
- 目录型:某个业务模块报错,通常是应用或数据库问题
- Bot 触发型:只有特定爬虫和特定路径报错,通常是 WAF、限流或规则误伤
5.5 软 404
软 404 常见于:
- 页面返回 200,但内容写着“页面不存在”
- 模板页返回 200,但正文为空
- 搜索结果为空时也返回 200
日志分析时,软 404 不能只靠状态码发现,必须结合正文模板和页面标题一起判断。
六、抓取预算怎么估算:用日志推断“重要页面抓取是否不足”
6.1 先定义“重要页面”
不要把所有 URL 平等看待。建议先用页面意图做分层。你可以结合 Intent 工具 给 URL 标注成:
- 信息型
- 交易型
- 商业比较型
- 支持文档型
- 本地服务型
这样你在看日志时就能回答:抓取量是被重要商业页占用,还是被低价值模板页占用。
6.2 估算口径
建议每周输出这几个指标:
- 索引候选页的 bot 覆盖率
- 核心页面的平均再抓取间隔
- 参数页 / 非参数页抓取比例
- 5xx 占比
- 404 在已知旧 URL 中的占比
- 重要目录的抓取集中度
如果你用的是数据仓库,把这些指标按模板、目录和 bot 家族拆开,就能很快找出“抓取预算被谁拿走了”。
6.3 判断抓取不足的典型信号
- 首页和核心分类页抓取很少
- 新上架产品、最新文档、最新案例迟迟不回访
- sitemap 已更新,但 bot 访问没有跟上
- 服务器响应慢,bot 访问时间分散且频繁失败
- 大量抓取集中在低价值参数 URL 上
6.4 修复顺序
排查顺序建议固定化:
- robots.txt / noindex / canonical 是否正确
- 内链是否把重要页埋得太深
- sitemap 是否只放可索引规范 URL
- 页面响应时间是否过高
- 5xx / 404 是否在拖累抓取
- 参数 URL 是否需要收敛
七、日志分析脚本:从采集到聚合,先把口径跑通
7.1 Nginx 日志配置示例
下面这段配置会把抓取分析需要的字段一次性打出来:
log_format seo '$time_iso8601\t$remote_addr\t$http_x_forwarded_for\t$host\t$request_method\t$request_uri\t$status\t$body_bytes_sent\t$request_time\t$upstream_response_time\t$http_referer\t$http_user_agent';
access_log /var/log/nginx/access.seo.log seo;
作用说明:
- 用制表符分隔,方便后续用 Python、SQL 或 ClickHouse 直接解析
- 保留原始 IP 和转发 IP,便于识别 CDN / WAF 场景
- 同时记录请求耗时和上游耗时,排查 5xx 和慢请求更直接
- 保留 UA 和 referer,方便 bot 验证和异常来源分析
7.2 Python 解析示例
这段脚本做三件事:
- 过滤并验证 Googlebot / Bingbot
- 规范化 URL,去掉无意义追踪参数
- 按 bot、路径和状态码聚合异常
import socket
import urllib.parse
from collections import Counter
TRACKING_PARAMS = {
'utm_source', 'utm_medium', 'utm_campaign', 'utm_term',
'utm_content', 'gclid', 'fbclid', 'msclkid', 'sessionid'
}
def normalize_uri(uri):
parts = urllib.parse.urlsplit(uri)
path = parts.path or '/'
if path != '/':
path = path.rstrip('/')
query = urllib.parse.parse_qsl(parts.query, keep_blank_values=True)
query = [(k, v) for k, v in query if k.lower() not in TRACKING_PARAMS]
query.sort()
return urllib.parse.urlunsplit(('', '', path, urllib.parse.urlencode(query), ''))
def reverse_dns_ok(ip, suffixes):
try:
host, _, _ = socket.gethostbyaddr(ip)
if not host.endswith(suffixes):
return False
addrs = {item[4][0] for item in socket.getaddrinfo(host, None)}
return ip in addrs
except Exception:
return False
def bot_family(ip, ua):
ua_l = ua.lower()
if 'googlebot' in ua_l and reverse_dns_ok(ip, ('.googlebot.com', '.google.com')):
return 'googlebot'
if 'bingbot' in ua_l and reverse_dns_ok(ip, ('.search.msn.com',)):
return 'bingbot'
return 'other'
counts = Counter()
status_mix = Counter()
bad_urls = Counter()
with open('access.seo.log', 'r', encoding='utf-8') as f:
for line in f:
ts, ip, xff, host, method, uri, status, bytes_sent, rt, urt, referer, ua = line.rstrip('\n').split('\t', 11)
bot = bot_family(ip, ua)
if bot == 'other':
continue
path = normalize_uri(uri)
counts[(bot, path)] += 1
status_mix[(bot, status)] += 1
if status.startswith(('4', '5')):
bad_urls[path] += 1
print('Top URLs:', counts.most_common(20))
print('Status mix:', status_mix)
print('Problem URLs:', bad_urls.most_common(20))
7.3 这段脚本怎么用
- 先跑一天日志,确认 bot 识别和 URL 规范化是否正确
- 再按天批处理,把结果写入表或对象存储
- 最后补一个可视化面板,看 bot 家族、状态码、目录和模板的趋势
如果你的日志量很大,建议把 DNS 验证做成缓存或异步任务,不要在主线程里逐条查 DNS。
7.4 进阶做法
如果你已经把日志进了 ClickHouse、BigQuery 或 Elasticsearch,可以把同样的逻辑迁移成 SQL 聚合。核心原则不变:
- 先验证 bot
- 再规范化 URL
- 最后按目录、模板、状态码、日期维度聚合
八、把日志结论变成动作:告警、优先级和事故预防
8.1 你应该自动报警的项目
建议至少对这些指标设阈值:
- 5xx 占比连续 15 分钟高于阈值
- Googlebot / Bingbot 抓取量突然下降
- 参数 URL 占比突然上升
- 重要页面 72 小时未被再次抓取
- 404 在某个目录里集中爆发
- 单个目录的抓取耗时明显升高
8.2 事故预防建议
- 把抓取日志监控接入 Slack、飞书或邮件
- 发布前检查 canonical、robots、重定向和状态码
- 大规模改版时先在预发布环境跑日志回放
- 把“异常 URL 规则库”固化到中台或网关层
- 对新上线目录先做灰度,避免一夜之间把抓取预算打散
8.3 用业务优先级来排修复
不是所有问题都要立刻修。建议把修复优先级和影响面结合起来看。比如:
- 核心交易页 5xx:最高优先级
- 大量参数页浪费抓取:高优先级
- 单个旧 URL 404:中优先级
- 非核心页面的少量软 404:低优先级
如果你想把“修什么最值”这件事标准化,可以用 ROI Decision Workbench 把影响面、修复成本和预期收益放进同一张表,优先处理真正会影响抓取和索引的项。
九、行业落地清单:不同站点看什么最有效
9.1 电商
重点看:
- 商品详情页是否稳定回访
- 筛选、排序、分页是否占用过多抓取
- 下架商品是否长期返回 404 或链式跳转
- 类目页是否被大量参数组合稀释
9.2 SaaS
重点看:
- 定价页、功能页、集成页抓取是否充足
- 文档页更新后是否快速再抓
- 版本页、标签页、搜索页是否造成重复抓取
- 自动生成内容是否过多
9.3 B2B
重点看:
- 案例页、解决方案页、白皮书页是否被稳定抓取
- PDF 与 HTML 是否重复争抢抓取预算
- 地区页和行业页是否模板重复
- 询盘页、下载页是否被错误索引
9.4 本地服务
重点看:
- 门店页、服务页、城市页是否有足够抓取
- 地图参数、预约参数是否污染 URL
- 电话追踪参数是否制造重复页
- 地址、营业时间、服务范围是否更新后能及时被回访
十、最后一条实操原则
日志分析不是“找几个异常 URL”,而是建立一条稳定的工程链路:
- 采集统一
- bot 识别统一
- URL 规范化统一
- 状态码口径统一
- 告警口径统一
- 修复优先级统一
只要这条链路跑通,你就能用日志回答最关键的 SEO 问题:搜索引擎到底在抓什么,浪费在哪里,重要页面有没有被及时看到。
下一课可以继续看: