robots.txt、noindex、canonical 教程:什么时候该拦,什么时候该放
robots.txt、noindex、canonical 教程:什么时候该拦,什么时候该放
这是“SEO教程”系列第 11 课。前面我们已经讲了技术 SEO、页面速度、结构化数据,这一课继续往下解决一个极高频误区:很多团队把
robots.txt、noindex、canonical混着用,结果不是页面该收录的不收录,就是本来该拦的 URL 被大量抓取。
先给结论:robots.txt、noindex、canonical 解决的是三个完全不同的问题
很多人会把这三者混成一句话:
我不想让这个页面出现在 Google,就把它拦掉。
这句话通常会引发配置错误。
更准确的理解应该是:
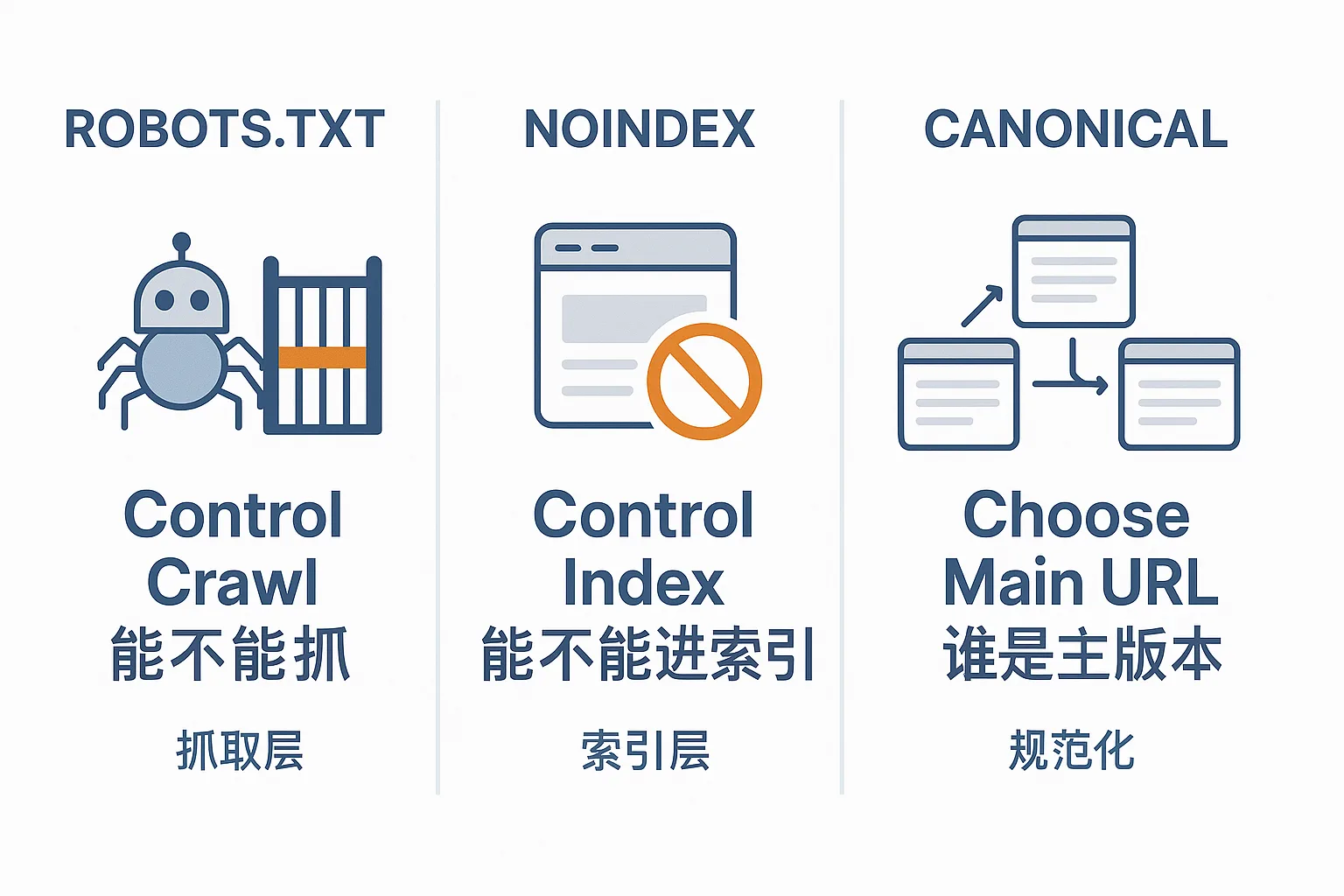
robots.txt:控制能不能抓noindex:控制能不能进索引canonical:控制重复内容中谁是主版本
这三个概念的边界必须分清。
如果只能记住一句话,就记住:
不想让页面被抓,不等于不想让页面被索引;不想让页面参与排名,也不等于应该把它 canonical 到别的页。
一、三者分别控制什么
robots.txt:控制爬虫访问路径
robots.txt 的作用是告诉爬虫:
哪些路径可以抓,哪些路径不要抓。
它属于抓取层控制。
但它不保证:
这个 URL 一定不会出现在索引里
因为如果页面已经被其他地方链接、被历史抓取过,或者有其他信号,搜索引擎仍可能保留 URL 级别的信息。
noindex:控制索引资格
noindex 的作用是告诉搜索引擎:
这个页面即使抓到了,也不要纳入搜索索引结果里。
它属于索引层控制。
前提是:
搜索引擎得先能抓到这个 noindex 信号
所以一个经典误区就是:
又 robots 拦掉,又想让搜索引擎读取 noindex
如果页面被完全禁止抓取,搜索引擎就可能根本读不到 noindex。
canonical:控制重复页面中的主版本
canonical 的作用是告诉搜索引擎:
这几个内容相近或重复的 URL 里,优先把哪个当主页面。
它属于规范化与合并信号。
它不等于:
把一个毫不相关的页面“重定向思维”地指向另一个页面
只有在内容相似、结构合理、语义接近时,canonical 才适合使用。
二、什么时候该用 robots.txt
适用场景
robots.txt 适合控制:
- 后台路径
- 登录路径
- 站内搜索结果页
- 某些明显无 SEO 价值的筛选组合
- 临时性系统路径
- 爬虫不需要反复访问的技术性路径
例如:
User-agent: *
Disallow: /admin/
Disallow: /login/
Disallow: /search/
Disallow: /cart/
这段配置解决的问题是:
- 避免后台、登录、购物车、站内搜索结果浪费抓取资源
- 减少无业务价值页面进入抓取队列
不适合的场景
robots.txt 不适合拿来做这些事:
- 想彻底让某页从 Google 消失
- 想表达“这个页面别索引”
- 想合并重复页面
例如你想让某个测试页彻底不进入索引,如果只写:
Disallow: /test-page/
并不能稳定达到“完全不索引”的目标。
常见错误写法
User-agent: *
Disallow: /
这段写法会直接把整站都拦住,生产环境里如果误发,非常危险。
实务建议
robots.txt先控制“抓取预算”和“路径边界”- 不要把它当成一切页面可见性问题的统一开关
- 改动后一定要检查:你是不是误伤了核心分类页、产品页、文档页或图片资源
三、什么时候该用 noindex
适用场景
noindex 适合这些页面:
- 低价值搜索结果页
- 站内过滤后的临时页
- 重复但又必须对用户开放的页面
- 隐私、条款、某些系统提示页
- 不想参与搜索但仍需可访问的页
最常见写法是 HTML 里的:
<meta name="robots" content="noindex, follow">
这段代码解决的问题是:
- 页面可抓取
- 页面内链仍可被跟踪
- 但页面本身不进入索引
什么时候可以用 X-Robots-Tag
如果不是 HTML 页面,例如 PDF、CSV、某些资源文件,可以用响应头:
X-Robots-Tag: noindex
这段配置解决的问题是:
- 对非 HTML 内容下发 noindex 信号
- 不依赖页面内
<meta>标签
常见错误
错误组合:
robots.txt 禁止抓取
+ 页面里写 noindex
这样做的问题是:
爬虫可能根本拿不到页面内容,也就读不到 noindex
所以如果你的目标真的是“不索引”,常见更稳的方式是:
允许抓取
+ 返回 noindex
代码示例
<head>
<meta name="robots" content="noindex, follow">
<title>站内搜索结果</title>
</head>
适合:
- 站内搜索页
- 某些低价值筛选页
- 不想让用户从 Google 直接进来的功能页
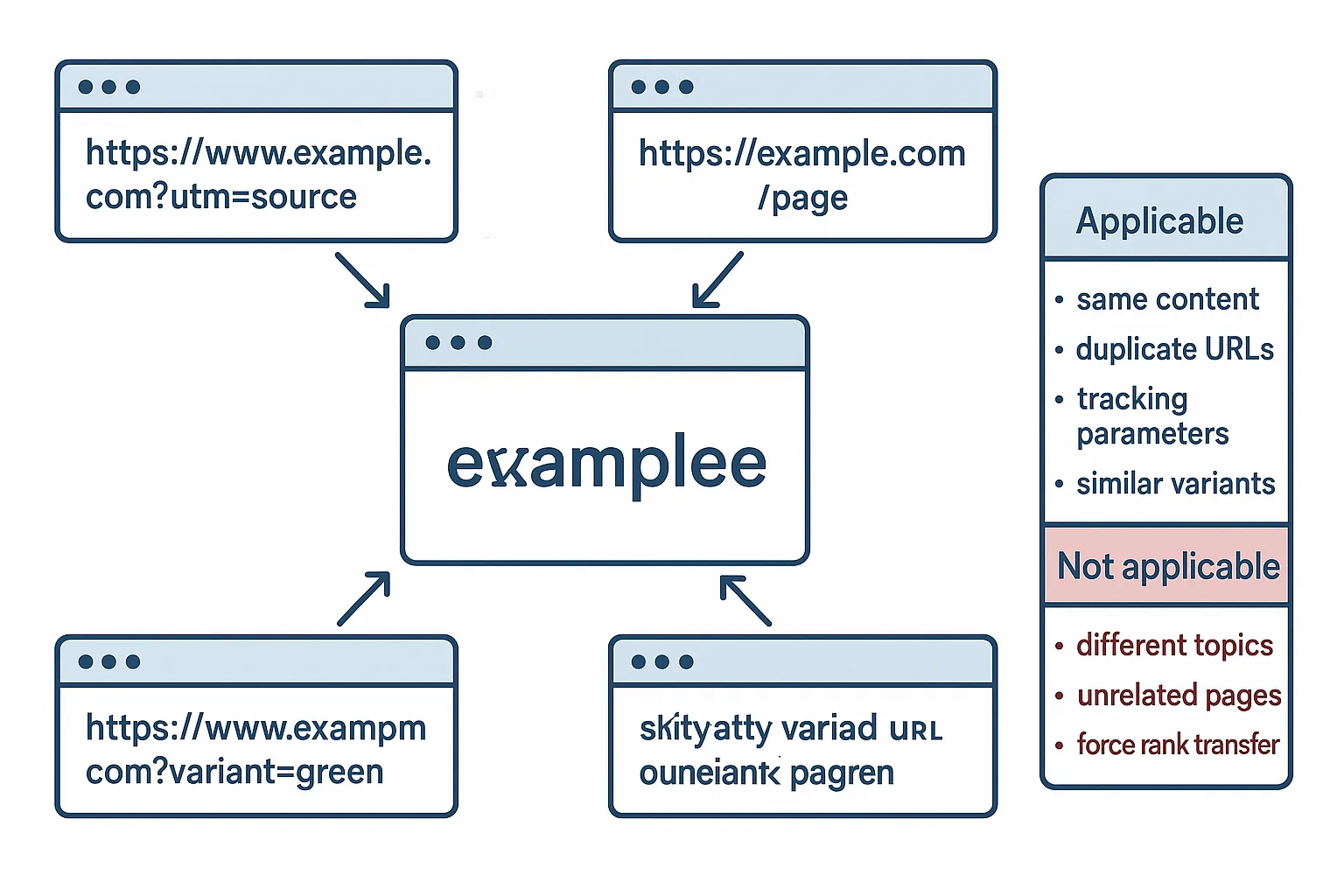
四、什么时候该用 canonical
适用场景
canonical 适合:
- 参数页和主页面内容高度接近
- 同一内容有多个 URL 版本
- 分析/跟踪参数造成重复 URL
- 产品轻微变体页内容高度一致
- 同一篇内容在不同路径下重复出现
最常见写法:
<link rel="canonical" href="https://example.com/category/seo-guide" />
这段代码解决的问题是:
- 向搜索引擎表达“这一组重复页里,主页面是哪个”
- 减少参数页、追踪页、复制页造成的重复信号分散
什么时候不要乱用
canonical 不适合:
- 完全不同主题的页面
- 只是想“把权重导给另一个高权重页”
- 类目页硬 canonical 到首页
- 多个强差异产品页都 canonical 到某一个产品页
这种误用会让搜索引擎收到矛盾信号,甚至导致真正该排名的页面失去资格。
代码示例
<head>
<title>SEO 教程 - 带参数版本</title>
<link rel="canonical" href="https://example.com/seo-tutorial" />
</head>
适合:
?utm_source=之类追踪参数版本- 排序参数不改变核心内容时的重复页
实务提醒
canonical 是提示信号,不是强制命令。
所以前提仍然要尽量保证:
- 内容相似
- 主版本明确
- 内链一致
- sitemap 优先提交主版本
五、三者怎么组合才合理
场景 1:站内搜索结果页
目标:
不希望进入索引,但页面仍可被访问
推荐:
- 页面不必写进 sitemap
- 页面可抓取
- 页面加
noindex, follow
不推荐:
- 直接 robots 禁掉后又想靠 noindex 清理索引
场景 2:电商筛选页
目标:
保留少数有搜索价值的筛选页,避免大量组合 URL 浪费抓取预算
推荐:
- 高价值筛选页可开放抓取和索引
- 大量低价值组合页可控制抓取或 noindex
- 内容近似的参数页可 canonical 到主分类页
这里不能一刀切。
如果你不确定哪些页值得保留,可以先用 ROI 决策工作台 评估页面价值,再决定哪些模板值得做技术维护。
场景 3:带追踪参数的内容页
目标:
不同 URL 不要分散信号
推荐:
- canonical 指向主 URL
- 不需要用 noindex 清理每个参数页
- 内链和 sitemap 只提交主版本
场景 4:测试环境或临时页
目标:
不让测试内容污染搜索结果
推荐:
- 最好直接权限隔离,不让外部访问
- 如果线上可访问,至少要明确 noindex
- 重要情况下再辅以 robots 控制
六、不同网站类型怎么用
电商网站
重点是:
- 分类页 / 筛选页 / 参数页
- 产品变体页
- 排序页
- 搜索结果页
电商最容易出问题的地方不是“没有 canonical”,而是:
canonical 乱指
筛选页全放开
站内搜索页被抓取
SaaS / 工具站
重点是:
- 文档页重复
- 模板页参数化
- 公开页与登录后页边界
- 功能页与营销页重复
SaaS 站点要特别小心:
同一内容被营销页、帮助页、功能页重复讲了一遍
B2B 网站
重点是:
- PDF 与 HTML 页面重复
- 多语言 / 多区域版本
- 案例页、产品页、行业页之间关系不清
内容站
重点是:
- 标签页
- 作者页
- 日期归档页
- 重复专题页
- 分页页
内容站很容易因为标签、归档、分页处理不好,导致大量低价值页进入索引。
七、上线前检查清单
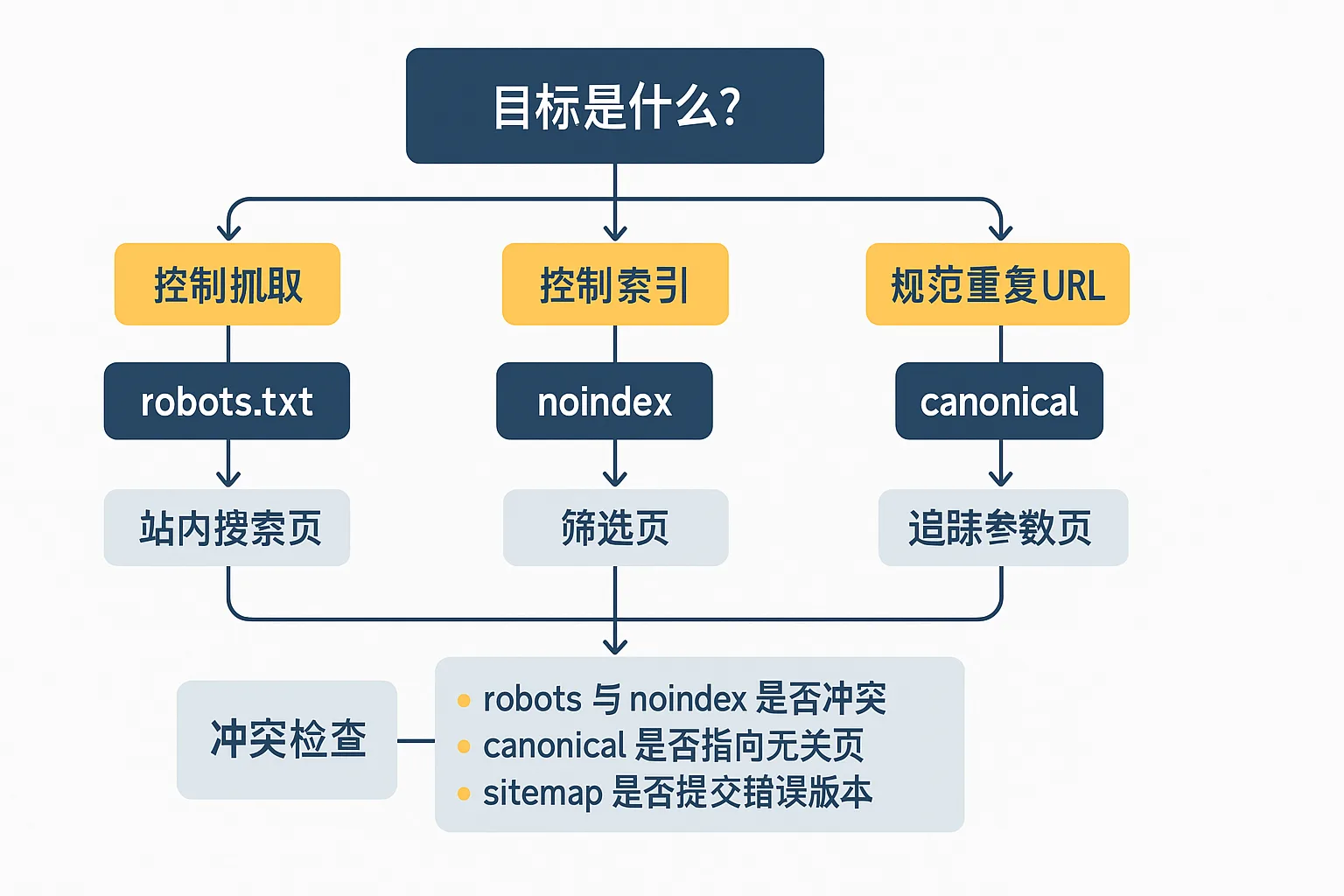
1. 先问目标
- 你是想控制抓取?
- 还是想控制索引?
- 还是想规范重复 URL?
2. 再选手段
- 控抓取:robots.txt
- 控索引:noindex
- 规范主版本:canonical
3. 再查冲突
- 有没有 robots 和 noindex 互相打架?
- 有没有 canonical 指向无关页面?
- sitemap 有没有提交错误版本?
- 内链是不是还在大量导向非主版本?
八、代码示例汇总
robots.txt 示例
User-agent: *
Disallow: /admin/
Disallow: /login/
Disallow: /search/
作用:控制无价值路径被抓取。
noindex 示例
<meta name="robots" content="noindex, follow">
作用:允许抓取,但页面不进索引。
canonical 示例
<link rel="canonical" href="https://example.com/seo-tutorial" />
作用:把相近重复版本合并到主 URL。
九、结论:先搞清目标,再决定拦什么、放什么、并什么
如果只能记住一句话,就记住:
robots.txt 不是 noindex,noindex 不是 canonical,三者不能互相替代。
真正成熟的技术 SEO 不是“把不喜欢的页面都拦掉”,而是:
- 该抓的让它抓
- 该进索引的让它进
- 该合并的正确合并
- 该清理的用合适方式清理
下一课我们继续: